

1. 서 론
2. 연구 방법
2.1 종분포모델을 위한 입력자료 구축
2.2 변수선택방법
2.3 종분포모델 결과 비교를 위한 실험 설계
3. 결과 및 고찰
3.1 모델 정확도
3.2 실제 서식지와 모델 결과의 비교
3.3 변수중요도
4. 결 론
1. 서 론
기후변화에 따른 영향이 확대되면서, 탄소중립, 자연기반해법 등 생태계 기반의 기후변화 대응 정책이 제안되고 있다. 이러한 정책을 지원하기 위해서는 생태계에 대한 기후변화 리스크에 대한 평가가 우선적으로 되어야 한다. 특히, 기후변화 적응 차원에서 우리나라는 ‘국가기후변화적응대책(Ministry of Environment 2015, 2020, 2023)’을 통해 생태계 분야를 포함한 여러 부문에 대하여 기후변화 리스크를 제시하고 각 리스크에 대응한 정책적 관리 및 저감 정책들을 요구하고 있다. 기후변화 리스크 평가가 실질적 정책과 연계되게 하기 위해서는 정량화된 평가 방식의 개발이 무엇보다 중요하다(Chae et al. 2021). 생태계 분야에 대한 정량화된 리스크 평가 연구는 생태적 자원의 감소 즉, 종의 감소로 인한 생물다양성 감소 등의 진단에 필요한 종별 기후변화 취약성 평가, 시스템의 붕괴를 주제로한 침입 외래종의 생태계 교란 위험도 평가 등을 들 수 있다(Kim et al. 2018, Hong et al. 2020). 종 수준의 기후변화 영향은 그중 종별 기후변화 취약성 평가, 종의 서식지 보존 및 복원 등과 관련해서는 생물종의 위치조사정보와 환경정보 간의 상관성을 바탕으로 하는 접근법(correlative approaches)이 활발히 이용되고 있다. 이는 주로 ‘종분포모델(Species Distribution Model)’이라고 칭한다(Pacifici et al. 2015, Foden et al. 2019).
종분포모델의 입력자료는 생물종의 위치조사자료와 이와 연관된 환경자료이다. 환경자료, 특히 기후자료의 경우, 주로 19가지 생물기후변수(Bioclimatic variables, BIO) 내에서 선택되어 사용된다(Bryn et al. 2021). 생물기후변수는 월평균 기온과 강수량을 기반으로 생물의 분포에 영향을 미치는 평균적인 기후, 계절성, 극한 및 제한적 기후를 나타내는 지표로 개발되었기 때문이다. 그러나 여기서 한가지 짚어봐야할 점은 이 19가지 생물기후변수가 생물의 생리생태학적 과정(ecophysiological process)에 영향을 주는 변수들을 적절히 대체하여 표현되고 있는 것인가에 관한 것이다. 예를 들어, 식물의 생장에 중요한 기온, 수분, 양분, 광, 이산화탄소 등을 직접 이용하는 것이 모델의 결과와 해석에 있어 신빙성을 더해줄 수 있을 것이다(Austin and Van Niel 2011). 그러나 식물이 이용할 수 있는 ‘수분’에 관해서 생물기후변수는 강수량을 통해서만 표현된다. 실제로 대부분의 육상 식물이 뿌리를 통해 수분을 흡수하기 때문에, 식물의 이용가능한 수분은 지표 부근의 토양수분과 연관성이 크다(Wolf 2011). 이러한 토양수분을 측정하는 것에는 한계가 있기 때문에, 생물기후변수에서는 식물이 이용할 수 있는 수분은 강수량을 통해 나타났었다. 하지만 이는 지표면에 강수량을 통해 유입된 수분이 증발산현상을 통해 유출될 수 있다는 점을 고려하지 않는다. 이러한 이유로 강수량과 잠재증발산량을 함께 사용한 수분수지(water balance, 강수량과 잠재증발산량의 차)가 식물의 종 분포에 영향을 주는 주된 요인으로 분석되기도 하였다(Crimmins et al. 2011, Barbet‐Massin and Jetz 2014). 이 뿐 아니라, 생물기후변수에서는 계절에 대해서는 주로 여름철과 겨울철 기온을 나타내고 있기 때문에, 식물계절과 관련된 봄 및 가을철 기온에 대해서는 배제되고 있다. 봄철과 가을철의 기후특성은 식물 생장의 시작과 끝에 중요한 영향을 주는 요소로 알려져 있으며, 특히 구상나무와 같은 침엽수림의 경우 봄철 기온 상승과 토양수분 상태의 악화가 쇠퇴의 원인으로 지목되고 있다(National Institute of Forest Science 2018). 하지만, 토양환경의 수문학적 변화를 야기하는 계절간 강수량 재분배 효과 등이 전통적 생물기후변수에서는 뚜렷하게 구현되지 못하는 경향이 있다(Bede-Fazekas and Somodi 2020). 이러한 점들을 고려해보았을 때 19가지 생물기후변수가 식물의 성장 및 분포에 영향을 미치는 적절한 기후변수 목록인가에 대해서 생각해볼 필요가 있다.
다음으로 고려해보아야 할 점은 모델에 입력할 변수를 선정하는 과정이다. 대부분의 경우, 생물기후변수 간의 상관분석을 실시한 후, 상관계수가 낮은 변수(예, 피어슨 상관계수 0.7 미만) 중에서 그 종의 생리생태학적 연구결과 등 다양한 문헌을 참고하여 모델에 최종적으로 입력할 생물기후변수를 선택하게 된다 이러한 과정을 통해 다중공선성이 낮으며, 노이즈(noise)와 중복성이 적고 목적변수와의 연관성이 있는 입력변수를 선택하므로서, 모델의 복잡성을 낮추고 과적합을 방지할 수 있기 때문이다(Brun et al. 2020, Effrosynidis and Arampatzis 2021). 하지만 대부분의 생물종은 변수선택 과정에서 참고할 만한 선행연구 결과를 찾아보기 힘든 경우가 많다. 그럼에도 불구하고 이러한 종을 대상으로 모델을 구축해야 한다면, 연구자의 주관에 따라 환경변수가 선정될 가능성이 높으며 이러한 과정을 거쳐 구축된 모델의 정확도가 일정 수준 이상이라고 하더라도 여전히 결과에 의문이 남아있을 수 있다.
최근 드론, 위성영상 등을 이용하여 환경 데이터 취득방식이 다양해지고 있으며(Randin et al. 2020), 심지어 월평균 기온과 강수량만으로도 잠재증발산량과 같은 생물의 생리생태학적 과정과 연관된 다양한 데이터를 생성할 수 있다. 이러한 추세에 맞추어, 기존의 19가지 생물기후변수 외에 종분포모델의 입력변수로서 잠재증발산, 적산온도 등의 변수를 생산하여 사용하고 있다(Barbet‐Massin and Jetz 2014, Li et al. 2022). 동시에 모델 구축 시 입력되는 정보가 중복되면 모델 정확도가 떨어지게 되므로, 빅데이터(Bigdata)속에서 변수 간의 중복된 정보를 최대한 배제하면서 목적변수와 연관성이 높은 특징(Feature), 즉 중요한 설명변수를 찾는 변수선택방법(Feature selection)이 다양하게 개발되고 있다(Effrosynidis and Arampatzis 2021).
빅데이터 속에서 적합한 변수를 탐색하는 변수선택방법은 본격적인 종분포모델을 구축하기 전에 ‘탐색적 데이터 분석(Exploratory Data Analysis)’ 단계에서도 유용하게 활용될 수 있다. 탐색적 데이터 분석은 데이터의 이상치 등의 처리뿐 만 아니라 데이터 내의 숨겨져 있는 패턴이나 변수 간의 관계 등을 발굴하기 위한 목적으로 이루어지는 데이터 전처리 과정의 일종으로, 시각화나 상관분석을 통해 설명성이 높을 것으로 예상되는 변수를 선택하는 것까지 포함된다(Komorowski et al. 2016). 탐색적 데이터 분석의 일환으로서 잠재적인 설명변수를 선택할 때 상관분석뿐만 아니라 머신러닝을 이용한 다양한 변수선택방법을 이용한다면, 특정 생물종의 분포에 대한 설명인자가 충분히 밝혀지지 않는 경우에도 데이터 상으로 종의 서식과 관련성이 높을 것이라고 기대되는 변수를 추출할 수 있으며, 설명력이 높은 모델을 구축하기 위한 방향성을 설정하는데 도움을 줄 수 있다. 그러나 종분포모델에 관해서는 변수선택에 관한 불확실성을 연구하거나, 탐색적 데이터 분석 관점에서 변수선택방법을 적용한 연구는 아직 많지 않다(Synes and Osborne 2011).
따라서 본 연구에서는 생태적 정보가 충분한 구상나무(Abies koreana)를 대상으로 다양한 기후변수와 변수선택방법을 적용하여, 구상나무의 분포에 중요한 설명변수를 탐색할 수 있는지, 그리고 어느 정도 신뢰성 있는 모델 결과를 생산할 수 있는지 확인하고자 한다. 특히 생물기후변수 외의 기후변수(기후빅데이터)를 사용함과 동시에 다양한 변수선택방법을 적용하여 탐색적 데이터 분석 단계에서 종분포모델을 이용하였을 때 변수 중요도를 기준으로 선정된 변수들이 기존에 알려진 구상나무의 생리생태학적 정보와 유관한지를 비교하려 한다.
2. 연구 방법
2.1 종분포모델을 위한 입력자료 구축
2.1.1 모델 대상종 및 출현자료
본 연구에서는 전국에 서식하는 토착 식물 중에서 기후변화에 민감하다고 알려져 있으면서, 종분포모델을 이용한 다수의 연구결과가 있는 구상나무를 대상으로 하였다. 구상나무는 아고산 지역에 주로 서식하는 대표적인 침엽수종이면서 우리나라 고유종이다. 자생지인 지리산과 한라산 등에서 서식지 및 개체수 감소, 고사목 증가 등 쇠퇴 현상이 나타나고 있는 것이 관찰되었는데, 이는 기온 상승 혹은 토양수분 부족 등 기후변화와 관련성이 높을 것으로 추정되고 있다(Koo and Kim 2020).
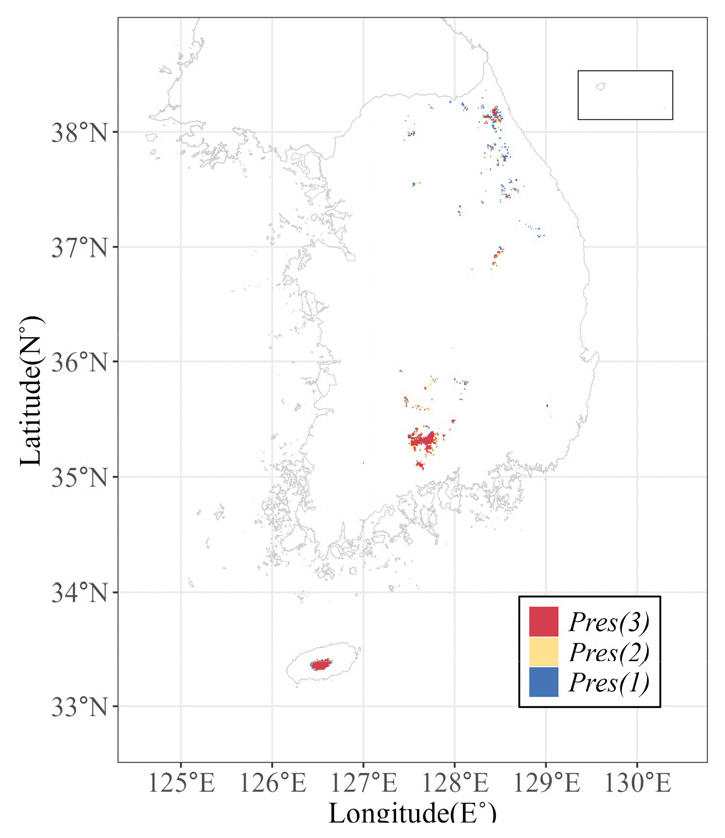
종분포모델에서 핵심이 되는 생물종 출현자료는 국립생태원의 전국자연환경조사를 포함하여, 국립생물자원관, 국립공원 공단 등 환경부 산하 유관기관이 보유하고 있는 식물종 조사 자료를 통합한 자료를 이용하였다(Hong et al. 2023). 생물종 위치자료는 2000년 이후에 급격히 증가되었다는 점과 기후자료가 2000 ~ 2019년의 기간을 이용할 수 있다는 점을 고려하여, 생물종 출현자료는 기후자료와 동일한 기간의 자료를 이용하였다. 해당 기간 동안 구상나무는 174개의 출현지점 수를 보였으며, 문헌 상에서 자생지로 알려진 지리산, 한라산, 덕유산, 가야산, 속리산, 소백산 등의 지역에서 해발고도 약 1000 m 부근에 분포하고 있었다(Fig. 1).
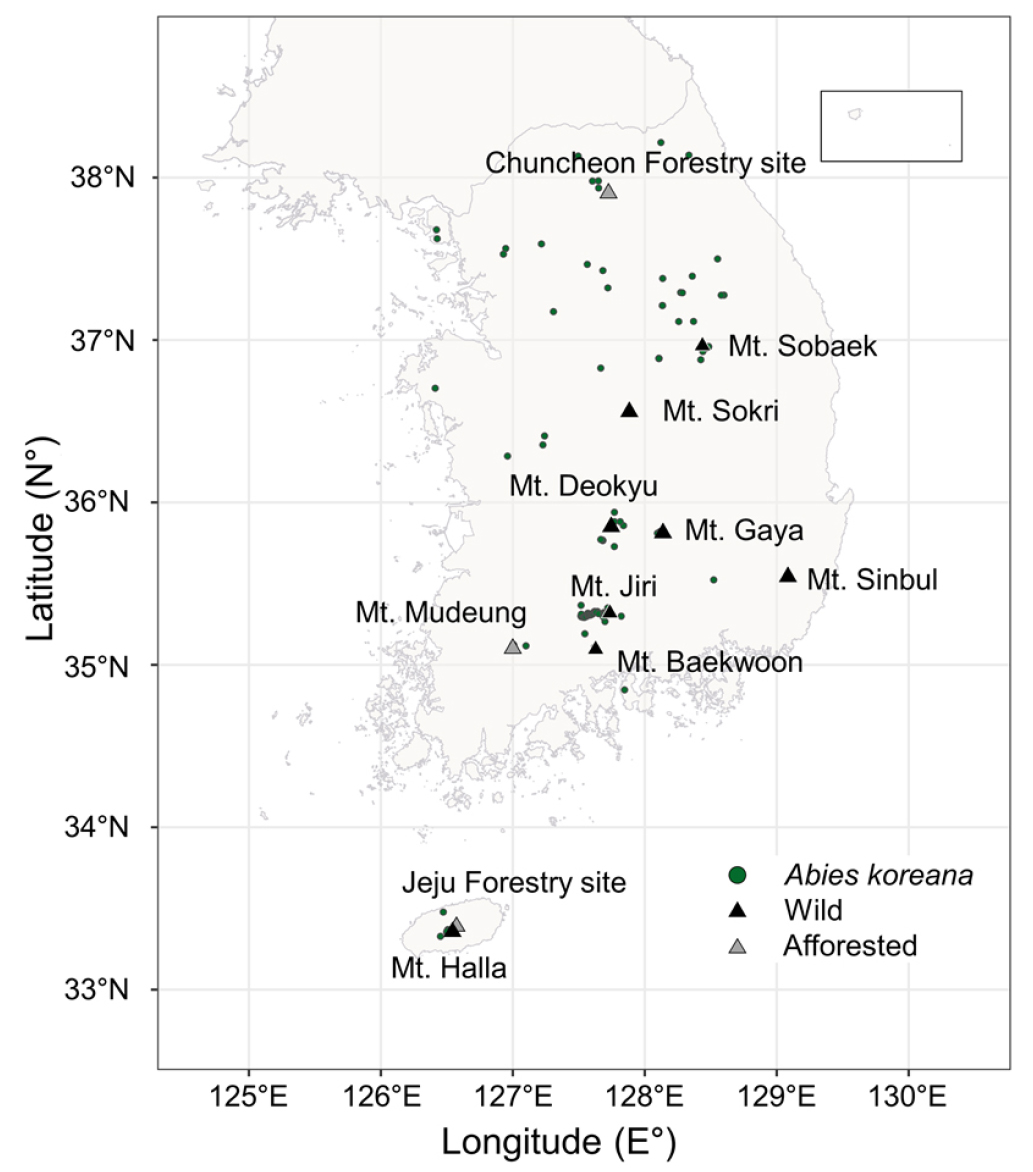
Fig. 1.
Presence data for Abies koreana used in this study (●), along with the known habitat of the species (▲). Three afforested areas are colored grey (modified from Koo and Kim (2020)).
2.1.2 지형자료
지형자료의 경우, NASA에서 제공하는 SRTM (Shuttle Radar Topography Mission)의 DEM (Digital Elevation Models)을 이용하여(NASA Earth Data 2000), 지형기복(relief)을 나타내는 변수로서, DEM 자료를 기반으로 경사, 향, 곡률(curvature), TPI (Topological Position Index), VRML (Local vector ruggedness Measure)을 ARC-GIS Pro (v.3.1) 프로그램을 통해 산출하였다. 구상나무의 종분포모델에 대한 선행연구에서 고도는 모델의 입력변수로 이용된 경우가 다수 있었으나(Park et al. 2015, Cho et al. 2015, Koo et al. 2017a, Lee et al. 2023b), 본 연구에서는 입력변수로 사용하지 않았다. 고도가 지형변수를 생성하는 기본이 되면서 육상의 기온을 나타내는 프록시이기 때문이다(Lee et al. 2023a, Bryn et al. 2021).
한편, 토양수분과 관련하여 TWI (Topographic Wetness Index, 토양습윤지수)을 계산하였다. 또한 수계까지의 거리가 전지구 및 대륙 규모의 육상식물의 분포에 중요한 기여를 했다는 Bradie and Leung (2017)의 연구결과를 참고하여, 하천과의 수평적, 수직적 거리를 계산하여 지상 및 지하에서의 수계의 접근성을 입력변수에 포함하였다. 하천에서의 수평적 거리는 물환경정보시스템(Water Environment Information System 2015)에서 제공하는 하천 네트워크 공간자료(Korean Reach File)를 이용하여, 하천과 DEM 격자의 중심점까지의 유클리디안 거리를 계산하였다. 한편, 하천에서의 수직적 거리는 SAGA (System for Automated Geoscientific Analyses) 프로그램(v.9.2.0)의 ‘Vertical Distance to Channel Network’을 이용하였다. 이는 간접적으로 지하수의 이용가능성을 보여주는 지표이다(Böhner and Antonic 2009).
식생의 에너지원으로 중요한 일사량은 경사, 향, 고도, 위도 등에 영향을 받는다. 이러한 잠재적인 일사량을 추정하기 위해, HLI (Heat Load Index)을 R 프로그램(v.4.3.1)의 SpatialEco 패키지(v.2.0)를 통해 계산하였다. 추가적으로 기상청의 주풍향 격자자료(Open MET Data Portal 2021)와 DEM 자료를 기반으로 바람노출지표(Wind exposure index)을 계산하였다. 바람노출지표는 풍상측(Windward side) 및 풍하측(Leeward side)을 나타내는 지표로, 구상나무의 성장이 바람의 영향을 받는다는 연구결과에 따라(Seo et al. 2021), 우리나라 월별, 계절별, 연 주풍에 대하여 해당 사면에 대한 바람의 영향을 나타내고자 하였다.
여기서 사용된 지형변수의 공간해상도(30 m)는 기후변수(1 km)와 일치하지 않기 때문에, 종분포모델에 이용되기 전에 두 자료 간의 해상도를 일치시켜야 할 필요가 있다. 그러므로 본 연구에서는 기상청 PRISM 자료를 기반으로 한 1 km의 공간해상도를 기준으로, 지형 및 토양 관련 변수의 공간해상도를 변경하는 방법(resampling)을 시도하였다. 이때, 지형 관련 정보가 최대한 손실되는 것을 막기 위해, 우선적으로 원천자료의 해상도를 기반으로 변수를 구축한 후, 10 m의 격자로 세분하여 1 km 격자 내 포함된 격자의 대푯값인 평균으로 나타내었다.
2.1.3 기후자료
기후자료는 기상청에서 제공하는 PRISM 자료를 이용하였다(KMA Climate Information Portal 2022). 이는 공간해상도 1 km의 격자 자료로, 지형, 지리적 요인 등의 미기후 영향 인자를 고려하여 생성한 격자 자료이다. 해당 기후자료의 월 자료를 이용하여 19가지 생물기후변수와 각 기후요소(최저기온, 최고기온, 평균기온, 풍속, 일사량, 상대습도)의 연평균, 계절평균(봄, 여름, 가을, 겨울, 식물성장기(4 ~ 11월)), 월평균 값을 계산하였다. 이때 월 자료의 20년(예, 2000 ~ 2019년)간의 누년평균값을 이용하였다. 또한, 월별 누년평균값을 기반으로, 우리나라의 식생대와 기후를 연관시킨 복합지수(온량지수, 한랭지수, 최저기온지수, 유효강우지수, 건습지수)와, 물순환을 고려한 수문학적 지수(건조지수, 기후학적 물수지, 기후학적 잠재토양수분량, 토양수분 부족량)을 산출하여, 식물의 성장과 관련된 기후빅데이터를 구축하였다(Oh et al. 2024).
2.2 변수선택방법
본 연구에서는 종분포모델에서 다양한 변수선택방법을 적용한 선행연구를 바탕으로 피어슨 상관분석, SHAP (SHapley Additive explanation), Embedded Random Forest 방법을 선택하여 적용하였다(Čengić et al. 2020, Effrosynidis and Arampatzis 2021).
2.2.1 피어슨 상관분석
종분포모델을 구축할 때 환경변수를 선택하기 위해 피어슨 상관계수를 주로 이용하고 있다(Brun et al. 2020). 구상나무를 대상으로 한 대부분의 선행연구에서 또한 19가지 생물기후변수의 다중공선성을 줄이기 위한 목적으로 피어슨 상관계수(|r| > 0.7)이 변수선택방법으로 사용되었다(Park et al. 2019, Lee et al. 2023a). 본 연구에서 또한 데이터가 지닌 모든 공간(즉, 남한)을 대상으로 상관분석을 진행하였으며, R 프로그램(v.4.3.1)의 caret 패키지(v.6.0)의 findCorrelation 함수를 이용하여 변수를 제거하였다. 이 함수는 상관계수의 절댓값이 0.7 이상인 변수의 쌍(pair)을 찾고 둘 중에 다른 변수와 상관계수가 큰 변수를 제거하는 방식으로 작동된다.
2.2.2 SHAP
SHAP는 각 선수가 게임의 결과에 미치는 영향을 측정하는 게임이론(game theory)을 기반으로 하는 방법이다(Fryer et al. 2021). 각 독립변수가 모델 예측 결과(즉, 한 격자에서의 예측값)에 긍정적 혹은 부정적 영향을 얼마나 기여하였는지를 shapley value을 통해 나타난다. 모든 예측지점에 대한 shapley value을 절댓값으로 변환한 후의 평균값은 각 변수의 중요도를 나타내며, 이를 이용하여 머신러닝의 입력변수를 선정하는데 효과적이라 알려져있다. Effrosynidis and Arampatzis (2021)은 어류와 관련된 환경데이터를 이용하여 여러 변수선택방법을 이용한 결과, 단일방법 중에서는 안정성과 모델성능 모두가 우수하다고 언급한 바가 있다. 본 연구에서는 랜덤 포레스트 모델을 기반으로 SHAP을 적용하였다. 랜덤 포레스트 모델을 구축할 때, 비출현 데이터는 랜덤으로 추출하였으며, 100개의 랜덤 포레스트 모델을 구축하여 Shapley value의 값을 평균하였다. SHAP 방법을 이용한 변수 선택과정도 Embedded Randomforest 방법과 동일하게 진행되었는데, 랜덤 포레스트 모델 구축 전, 상관계수의 절댓값이 0.9 이상인 변수를 제거한 후에 SHAP 방법을 통해 상위 75%p 이상의 변수를 추출하였다.
2.2.3 Embedded Random Forest
Embedded Random Forest 기법은 랜덤 포레스트 알고리즘에 함유된 변수 중요도를 기반으로 변수를 선택하는 방법이다(Rodriguez-Galiano et al. 2018). 랜덤 포레스트는 대표적인 tree 기반의 앙상블 알고리즘으로, 각 tree는 불순도(impurity)가 최소화되도록 node를 분할하여 대상을 분류한다. 이 과정에서 특정 변수가 해당 tree에서 불순도를 얼마나 감소시켰는지가 계산되며, 모든 tree에서의 평균 불순도 감소 지표(Mean Decrease Gini)는 변수가 예측결과에 미치는 중요도를 나타낸다. 랜덤 포레스트 모델을 구축하기 전에, 선형적 상관성이 높은 기후 및 지형 변수는 상관분석을 통해(|r| > 0.9)) 제거하였다. 이후, 비출현자료의 추출과정에서 나타나는 편향성(bias)을 최대한 배제하기 위해, 무작위로 추출한 비출현자료를 이용하여 랜덤 포레스트 모델을 100개 구축하였고, 변수별 평균 불순도 감소 지표의 평균값이 상위 75%p 이상인 변수를 선택하였다.
2.3 종분포모델 결과 비교를 위한 실험 설계
2.3.1 종분포모델 구축
앞서 언급한 3가지 변수선택방법을 두 가지 환경변수 후보군에 적용하여 두 가지의 실험으로 나누었다. 실험1은 환경변수 후보군에 본 연구에서 생성한 모든 기후변수(총 203개)와 지형변수를 지정한 것이다. 한편 실험 2에서는 실험 1에서의 지형변수를 동일하게 후보군에 포함시켰지만, 기후변수에서는 19개의 생물기후변수만을 후보군에 배정하였다. 두 후보군에 3가지 변수선택방법을 적용하여 6개의 앙상블 모델을 구축하였다. 상관분석을 통해 변수가 추출된 모델은 실험1-1과 실험2-1이며, SHAP와 상관분석을 결합하여 이용한 모델은 실험1-2과 실험2-2, Embedded Random Forest와 상관분석을 이용한 모델은 실험 1-3과 실험2-3으로 명명하였다. 모델들을 구성하는데 입력된 환경변수자료를 제외하고는 나머지는 동일한 절차로 진행되었다.
앙상블 모델 구축을 위해 진행된 절차는 다음과 같다. 출현자료의 경우, 출현격자 외의 격자에서 의사 비출현 지점(Pseudo-absence data)을 무작위로 출현자료와 동일한 수로 10번 추출하였다. 이렇게 생성된 출현 및 비출현 지점 데이터를 바탕으로 모델을 훈련시킬 용도(training data)와 검증할 용도(validation data)로서 7:3 비율로 무작위로 나누는 과정을 10번 진행하였다. 훈련용 데이터를 기반으로 R프로그램의 biomod2 패키지(v.4.2)에서 제공하는 11개의 알고리즘(ANN, SRE, FDA, MARS, GLM, GBM, GAM, CTA, XGBOOST, MAXENT, RF)을 모두 적용하여 1,100개의 단일 모델을 생성하였다(10회 비출현지점 무작위 추출 × 10회 훈련용 및 검증용 데이터 분할 × 11개 알고리즘). 이중 정확도(True Skill Statics, TSS)가 0.7 초과인 단일모델들을 기준으로 각 격자별 출현 확률값의 가중평균을 구하여 앙상블 모델을 형성하였다.
2.3.2 모델 결과 비교
위와 같은 절차로 형성된 앙상블 모델에 대해서 3가지의 결과를 확인해보았다. 첫 번째는 모델의 정확도이다. 검증용 데이터를 기반으로 TSS와 AUC-ROC (Area Under the Curve of receiver-operating characteristic) 기법을 이용하여 정확도를 평가하였다. AUC-ROC는 모델의 전반적인 분류 성능을 평가하는 지표이지만 국지적으로 분포하는 대상종에 대한 종분포모델링에서 높게 나오는 경향이 있다. 한편, TSS는 출현과 비출현 자료의 비율이나 자료 수집 면적에 영향을 받지 않기 때문에(Koo et al. 2016), 이 두 가지 지표를 통해 모델 성능을 확인하였다. 두 번째로 모델을 통해 예측된 구상나무의 출현 확률 분포도이다. 출현 확률 75% 혹은 90% 이상으로 나타난 지역을 잠재서식지로 정의하여, 잠재서식지의 수평적 분포와 수직적 분포가 알려진 자생지를 반영하는지를 확인하였다. 마지막으로 모델별로 모델의 성능에 영향을 미친 중요한 변수가 무엇이었는지 살펴보았다. 변수 중요도 측정은 permutation importance을 5회 반복한 평균값으로 나타내었다.
3. 결과 및 고찰
3.1 모델 정확도
실험1과 실험2의 총 6개의 앙상블 모델의 정확도를 비교하기 위해 y축을 AUC-ROC 값으로, x축에 TSS 값으로 하여 그래프로 나타냈다(Fig. 2). AUC-ROC는 0.948 ~ 0.975의 범위 내에서 나타나 모델이 대체로 적합도가 높게 나타났다. 가장 높은 값(0.975)은 많은 변수 후보군에서 상관분석을 이용한 실험1-1에서 나타났으며, 가장 낮은 값은 실험2에서 Embedded Random Forest 방법을 이용한 실험2-3으로 차이(약 0.027)가 크지 않았다. 실험1의 평균 정확도는 0.967로 실험2(0.955)보다 전반적으로 높은 정확도를 보였다.
모델 정확도의 또 다른 평가 기준인 TSS는 0.783 ~ 0.829 사이로, 모든 앙상블 모델의 결과는 실제 자료 간의 높은 일치도(TSS > 0.7)를 보였다. AUC-ROC 분포처럼 실험1의 TSS 평균은 0.805로 실험 2의 0.788보다 높은 값을 보이고 있다. TSS 값이 가장 높은 모델은 실험 1-1로, 상관분석을 이용한 모델이었으며, 그 다음으로는 상관분석과 SHAP 방법을 사용한 실험 1-2와 실험2-2가 높게 나타났다. 한편, 실험2의 상관분석을 이용한 모델(실험 2-1)은 가장 낮은 TSS 값을 보였다.
종합해보면, 실험1과 같이 변수 후보군이 더 많다면 그 종의 분포에 영향을 미친 적합한 변수를 찾을 확률이 높기에, 기존의 생물기후변수를 기반으로 하였을 때(실험2) 보다 모델 정확도를 높은 것으로 보인다. 또한, 상관분석 방법(실험1-1, 실험2-1)은 변수선택방법 중 간단하고 빠르며 효율적이면서도 상당한 정확도를 보장하고 있다는 것을 알 수 있다.
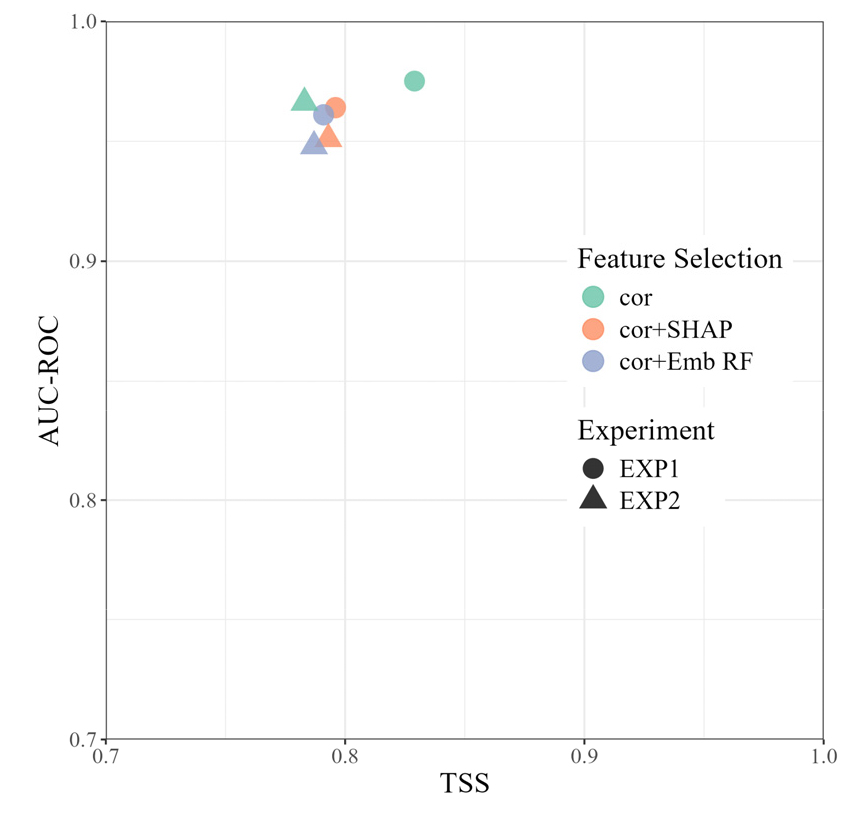
Fig. 2.
Model accuracy assessment by area under curve of the receiver operating characteristic curve (AUC-ROC) and true skill statistic (TSS). The abbreviations for each feature selection method are as follows: Pearson correlation method (cor); correlation method combined with Shapley additive explanation method (cor + SHAP); correlation method combined with embedded random forest (cor + Emb RF).
3.2 실제 서식지와 모델 결과의 비교
3.2.1 수평적 분포
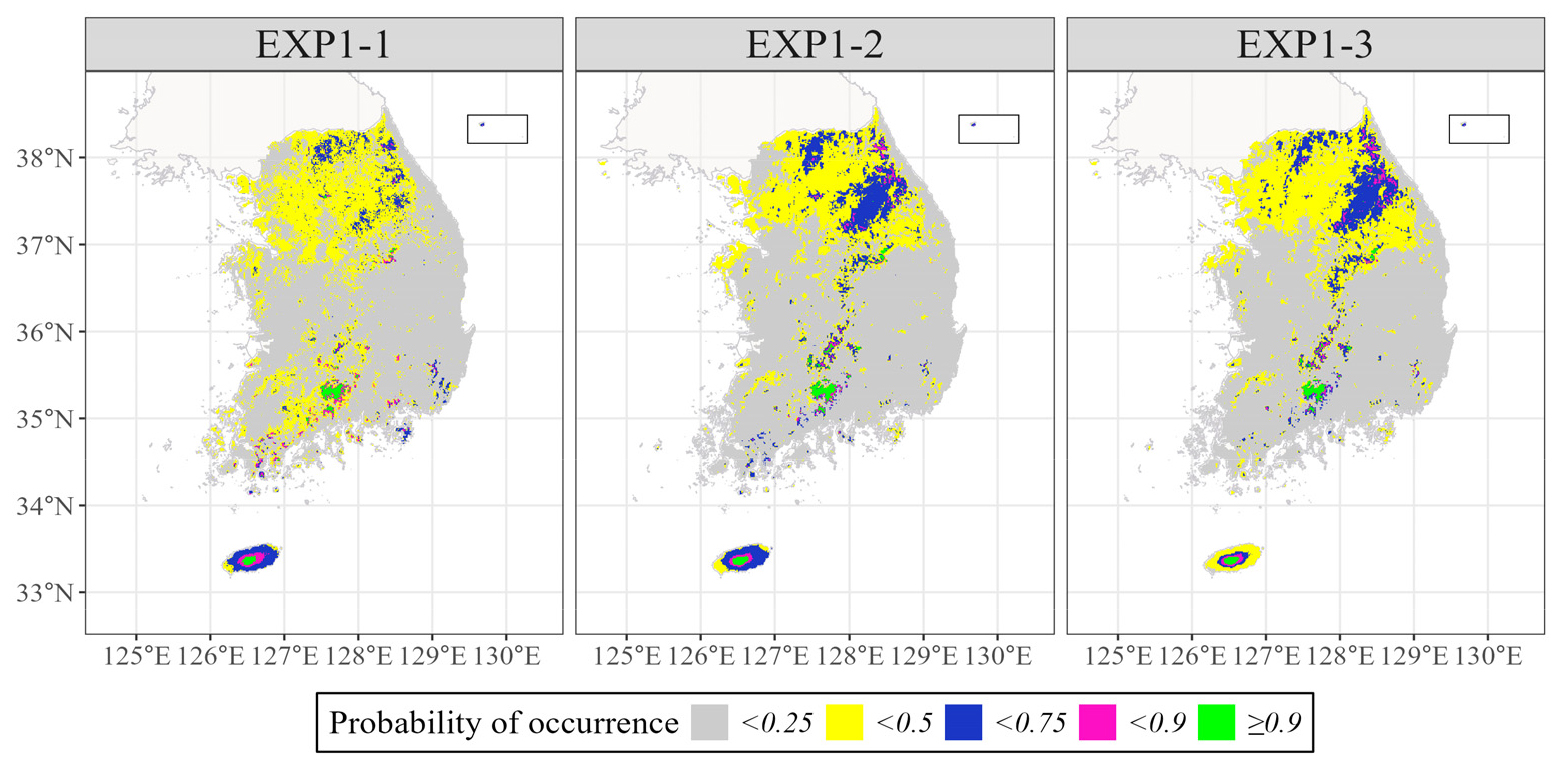
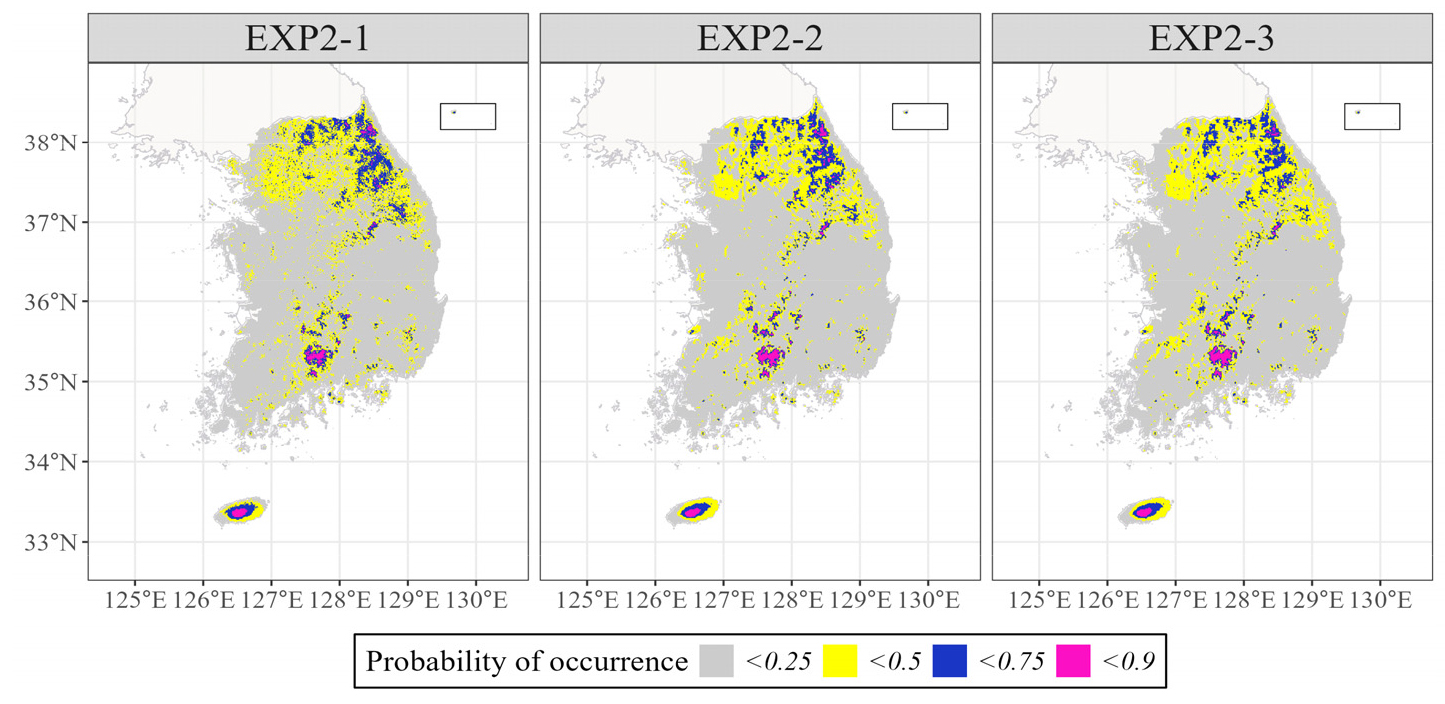
실험1에서 구축한 3개의 앙상블 모델을 바탕으로 구상나무의 분포 확률을 각각 예측하였다(Fig. 3). Fig. 4(a)는 해당 모델들의 결과에서 구상나무 출현확률이 90% 이상인 지점을 몇 개의 모델이 공통적으로 예측하였는지를 나타내는 지도이다. 구상나무 출현확률 90% 이상인 지역은 실제 구상나무의 서식지로 알려진 지리산, 한라산, 백운산, 가야산 일대를 공통적으로 포함하고 있었다. 그러나 예측된 분포가 모델별로 상이하게 나타났다. 한라산 및 지리산의 경우 고산·아고산 지역의 가장자리로 갈수록 출현확률 90% 이상인 지역을 예측한 모델 수는 점차 감소하였다. 한편, 문헌 상으로 알려진 구상나무의 자생지보다 광범위하게 분포를 예측하고 있었다. 예를 들어, 실험1-2와 실험1-3에서는 설악산, 오대산 지역을 예측하였다. 상관분석을 기반으로 변수를 추출한 실험1-1 모델에서는 장흥 천관산이나 완도에서도 구상나무의 존재 확률이 높게(> 90%) 예측되었다. 잠재서식지로 결정하기 위한 출현확률 임계치를 75% 이상으로 하였을 때, 잠재서식지는 임계치가 90%이상 일 때의 결과와 거의 유사하였다. 그러나 설악산, 소백산 부근을 살펴보았을 때, 다양한 입력자료군에 의해 훈련된 모델(실험 1-1, 1-2, 1-3)에서 이 지역을 잠재서식지로 판정하는 격자의 수가 증가하였으며, 그로 인해 공통적으로 이 지역을 예측하는 모델의 수가 대체로 1개에서 3개로 증가하였다(Fig. 4(b)).
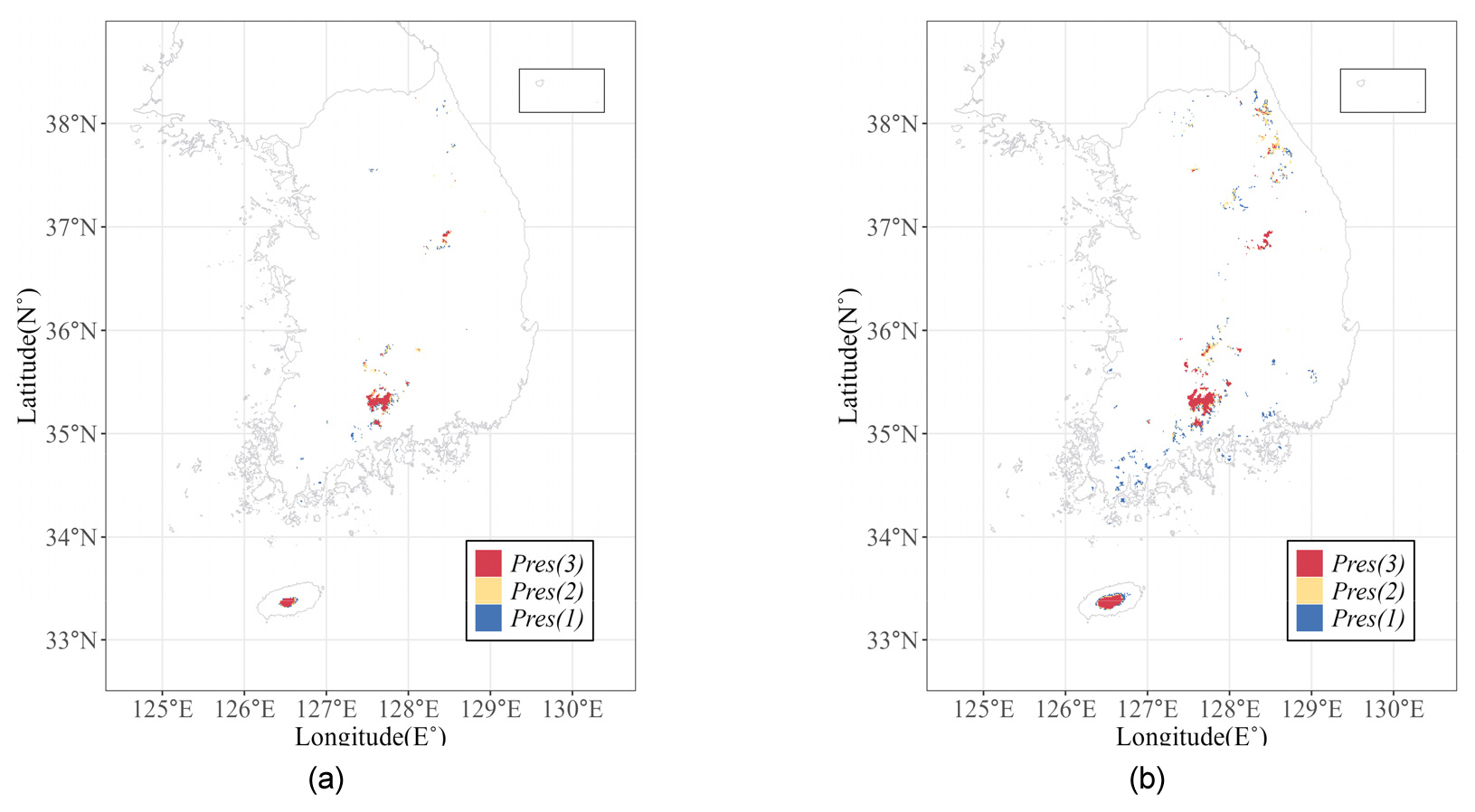
실험2 또한 대규모 자생지로 알려진 한라산과 지리산 영역에서 출현확률이 타지역에 비해 높게 나타났으나, 75 ~ 90%의 확률값이 나타났다(Fig. 5). 잠재서식지로 결정하기 위한 임계치를 75%로 하였을 때, 지리산과 한라산 일대가 모든 모델에서 공통적으로 예측된 것을 볼 수 있다(Fig. 6). 그러나 설악산, 오대산에서도 구상나무의 존재 가능성이 높다고 나타났는데, 해당 지역은 문헌상 알려진 것보다 광범위한 지역이다. 특히, 동일한 임계치(75%)에서의 실험1 결과와 비교해보면, 실험2의 모델은 설악산 지역에서 구상나무의 잠재서식지로 판단한 모델 수가 더 많았다.
3.2.2 수직적 분포
구상나무의 수직적 분포는 약 해발고도 1000 m 이상으로 알려져있다(Koo and Kim 2020). 본 연구에 이용한 구상나무 분포자료의 고도는 25.27~1737.09 m 사이에 있었으며, 평균 고도는 1091.86 m, 중위수는 1253.45 m 이었다. 고산 침엽수로서 상대적으로 낮은 고도를 보이는 출현지점 수도 있었으나, 제1사분위수(858.29 m)와 제3사분위 수(1451.5 m)를 보았을 때, 선행연구에서 언급되었던 해발고도 1000 m 지역에 평균적으로 분포하고 있음을 확인할 수 있었다. 따라서 본 연구에서는 모델을 통해 예측된 출현확률을 기반으로, 임계치(50, 75, 90%) 이상으로 나타난 지역을 잠재서식지를 정의하여 고도 분포를 살펴보았다(Fig. 7 and Fig. 8). 실험1의 모델에서는 임계치를 90% 이상으로 하였을 때, 잠재서식지의 평균 고도는 약 921.21 m로 알려진 고도와 비슷한 수치가 나타났다(Fig. 7). 전반적으로 상관분석을 통해 선택된 변수를 이용한 실험1-1에서는 타 모델에 비해 잠재서식지의 평균 고도가 다소 낮은 편(약 913.06 m)을 보이고 있었다. 상관분석과 Embedded Random Forest을 이용한 실험1-3의 모델에서는 평균 고도 969.3 m로 가장 1000 m에 근접한 잠재서식지를 예측하였다.
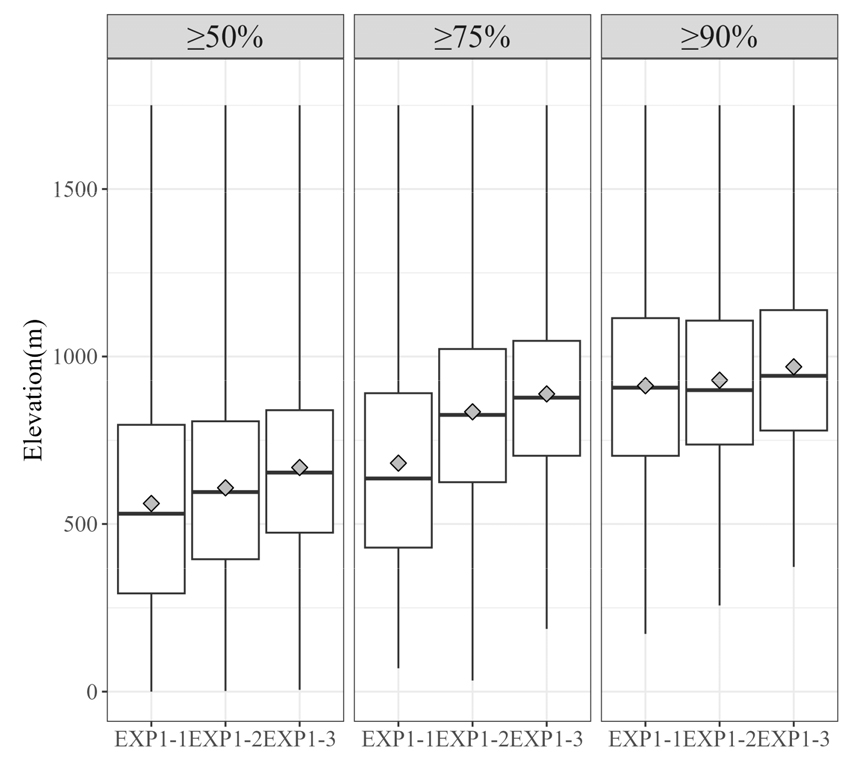
Fig. 7.
Box plots showing the elevation range of grid cells where the presence of Abies koreana was predicted by the ensemble models in Experiment 1. The grid cells were identified based on occurrence probability thresholds of 50%, 75%, and 90%. The diamond markers represent the mean elevation for each threshold category.
실험2의 3개 앙상블 모델 또한 임계치에 따라 잠재생육지의 고도가 어떻게 분포하고 살펴보았다(Fig. 8). 실험1과 달리, 출현확률이 90%가 넘는 지역이 존재하지 않았기 때문에(Fig. 5), 출현확률 50%와 75%를 임계치로 하였을 때 예측된 지역의 고도를 확인하였다. 출현확률 75% 이상을 잠재서식지로 하였을 때, 실험2에서 잠재서식지의 평균 고도는 954.31 m이었다. 그중 상관분석을 기반으로 하는 실험2-1에서 평균고도 992 m로 가장 1000 m에 근접하였으며, SHAP을 이용한 실험2-2와 Embedded Random Forest을 이용한 실험2-3은 각각 937.95, 933 m로 유사하게 나타났다.
실험1과 실험2의 모든 모델에서 구상나무의 대표적인 서식지로 알려져 있는 한라산 및 지리산의 아고산 지역에 대하여 타 지역에 비해 출현 가능성을 높게 예측하고 있었다. 임계치를 75% 혹은 90% 이상으로 하여 잠재서식지로 정의하였을 때, 잠재서식지 대부분은 고지대 산악지역에 분포하고 있었다. 그중에서도 실험2에 비해 실험1의 모델이 구상나무의 최대 자생지(한라산, 지리산, 덕유산, 소백산 등)를 높은 출현확률 값(90% 이상)으로 추정하고 있었으며, 그 외에 종분포모델에서 분포 예측이 어려웠던 속리산 등의 자생지 또한 출현확률 75% 이상일 때 나타났다(Koo et al. 2016). 앞선 모델 정확도 지표(AUC-ROC, TSS) 비교 결과와 함께 고려하였을 때, 실험1이 실험2보다 공간적 분포 예측 측면에서 알려진 서식지 분포와 근접하게 모의하고 있는 것으로 보인다. 그러나 실험1-1의 경우, 모델의 정확도 지표가 가장 높음에도 불구하고, 장흥 천관산 등 서식지로 알려지지 않은 지역이 포함되어 있어, 실제로 구상나무가 서식할 수 있는 환경인지는 현장조사를 통하여 알아볼 필요가 있다. 한편, 실험 1과 실험2의 대부분 모델에서는 설악산 지역에서 잠재서식지(75% 이상)로 예측되었는데, 이는 19가지 생물기후변수를 이용한 전국규모의 종분포모델 선행연구(Koo et al. 2016, Park et al. 2019)의 결과와 유사하였다.
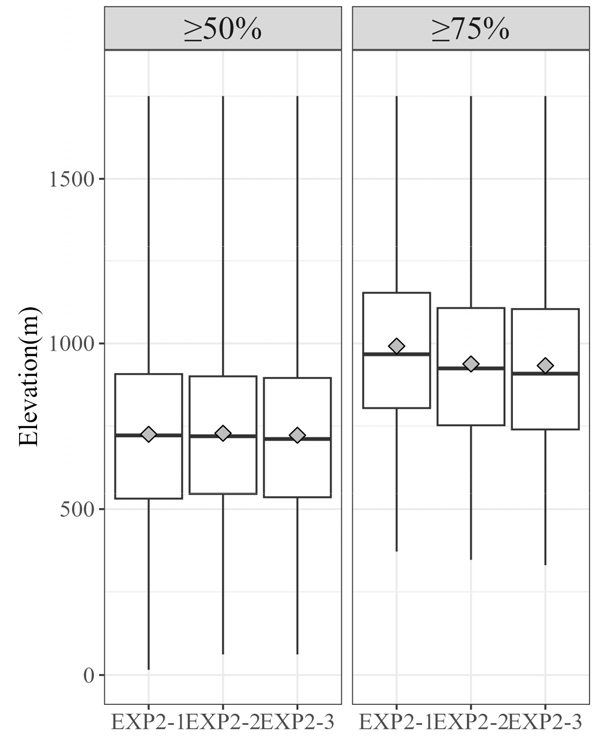
Fig. 8.
Box plots showing the elevation range of grid cells where the presence of Abies koreana was predicted by the ensemble models in Experiment 2. The explanation is the same as in Fig 7.
3.3 변수중요도
6개의 앙상블 모델에 입력된 변수들에 대하여 모델의 정확도에 미친 중요도를 각각 계산해보았다. Fig. 9은 모든 변수 후보군을 이용하여 변수 선택 과정을 거쳐 생성한 3개의 모델(실험1)에서 각 변수의 중요도를 계산하여 상위 10개까지 표시한 것이다. 상관분석을 이용한 실험1-1에서는 가장 중요한 변수로 잠재토양수분 부족량의 계절성(PSMD seasonality)이 선정되었다. 그 다음으로 7월 강수량(RN_07), 겨울철 상대습도(RHM_ DJF)가 중요한 변수로 선정된 것으로 보아, 해당 모델에서는 구상나무의 수분 이용가능성에 대한 중요성이 부각된 것으로 보인다. 상관분석과 SHAP방식이 결합된 실험 1-2에서는 9월 최고기온(TAMAX_09)이 가장 중요하게 나타났으며, 그 다음으로는 6월 강수량(RN_06), 잠재증발산량의 최솟값(PET_min), 겨울철 상대습도(RHM_DJF), 잠재증발산량의 최댓값(PET_max)로, 여름철과 겨울철의 수분이용가능성과 관련된 변수가 기온 다음으로 모델의 성능에 크게 기여한 것으로 나타났다. 상관분석과 Embedded Random Forest을 이용한 실험 1-3에서 또한 잠재증발산량 최솟값(PET_min), 겨울철 기후학적 토양수분(CMI_DJF), 잠재증발산량 최댓값(PET_max), 6월 강수량(RN_06) 순으로 중요도가 나타나 수분 이용가능성에 대한 중요성이 높게 나타났다.
19가지 생물기후변수와 지형자료를 후보군으로서 지녔던 실험2에서는 ‘여름철 기온’과 ‘여름철 강수량’이 구상나무의 분포 예측에 큰 영향을 준 것으로 나타났다(Fig. 10). 실험2-1에서는 가장 따뜻한 달의 최고기온(BIO5)이 가장 중요도가 높았으며, 그 다음으로는 가장 습한 달의 강수량(BIO13)이 높게 나타났다. 실험 2-2의 모델에서는 가장 따뜻한 분기의 강수량(BIO18), 가장 습윤한 분기의 평균기온(BIO8)이 중요한 것으로 나타났다. 실험 2-3에서의 변수 중요도는 실험 2-2와 거의 유사하게 나타났는데 이는 두 실험에 입력된 자료가 동일하기 때문인 것으로 보인다.
실험1, 실험2에서의 각 모델에서 공통적으로 중요하게 나타난 변수를 분석한 결과, 대부분의 모델에서는 지형변수보다 기후변수의 중요도가 높게 나타났었다. 특히 기온과 수분이용가능성에 대한 변수가 높은 중요도를 차지하였다. 특히 실험2에서는 여름철 기온과 강수량을 구상나무 분포에 있어 가장 중요한 변수로 보았다(Fig. 10). 여름철에 일사량이 증가하는 동시에 고온이 나타나면 구상나무에서는 광저해 현상이 나타나는 등 고온에 취약하기 때문이다. 또한 여름철 강수량은 토양에 지표에 수분을 공급하여 높은 일사량으로 인한 증발산량이 증가하여 토양수분이 부족해진 수분수지 불균형을 해소할 수 있다고 알려져 있다(Koo and Kim 2020).
이처럼 실험2에서는 식물의 활동이 활발히 일어나는 여름철 기온과 강수량은 광합성과 관련되어 구상나무 생존의 중요한 요소로 나타났으며, 실험1에서도 6, 9월의 최고기온, 6월 강수량 등 관련된 변수가 중요도 순 10위 권 안으로 나타났었다(Fig. 9). 그렇지만 Lee et al. (2023b)에서 실시한 전문가 설문조사에 의하면, 구상나무의 분포에 가장 중요한 변수는 봄철 성장기의 수분 스트레스이었다. 즉, 봄철에 일사량이 증가하면서 증발산량이 증가하지만, 강수량이 적어지는 기간이 길어져 가뭄이 나타나면 지표면의 수분이 부족해지기 때문이다(Koo and Kim 2020). 그러므로 겨울철 동안의 적설이 봄철 일사량 증가에 점차 녹으면서 성장 초기 수분스트레스를 해결해줄 수 있으므로, 겨울철 적설 또한 구상나무 생장의 중요한 인자로 인식되고 있다(Park et al. 2018). 이러한 겨울철 적설과 관련된 프로세스는 실험2보다는 실험1에서 도출된 중요 변수들을 통해서 도출할 수 있었다. 특히 실험 1-1에서는 중요한 변수로 선정된 잠재토양수분부족량 계절성, 겨울철 상대습도, 4월 일사량(SI_04) 등을 통해서 반영되고 있었다. 그러므로 생물기후변수만을 이용한 실험2보다 다양한 기후변수를 이용한 실험1에서 다양한 변수선택방법을 적용하였을 때, 새로운 생태생리학적 과정을 발견할 수 있는 가능성을 제공할 수 있을 것이라 보인다.
그러나 해석에 주의해야 할 점은, 모델의 결과만을 사용하였을 때는 이들 변수가 구상나무에 미치는 생리생태학적인 프로세스를 상세하게 설명하지 않는다는 점이다. 본 연구에서 사용한 변수중요도 측정방법(permutation importance)는 PCA (principle component analysis)나 선형 회귀(linear regression model)를 사용한 연구 결과와 같이, 변수가 연구대상과 어떠한 관계를 갖는지 알 수 없기 때문이다. 예를 들어서 일사량이 너무 강하지 않은, 60 – 70% 정도 그늘이 드리워진 환경이 구상나무의 초기 뿌리 성장에 중요하다고 알려져 있다(Park et al. 2024). 그러나 4월 일사량(SI_04)이 선택된 것 만으로는 이와 같은 추론은 불가능하다. 따라서 탐색적 데이터 분석(EDA) 관점에서 실험1과 같이 기후빅데이터를 사용한 종분포모델링을 진행해 보고, 해당 변수가 종의 분포와 어떠한 관계를 가지는지를 분석할 수 있는 후속 연구를 정밀하게 설계하는 것이 필요하다.
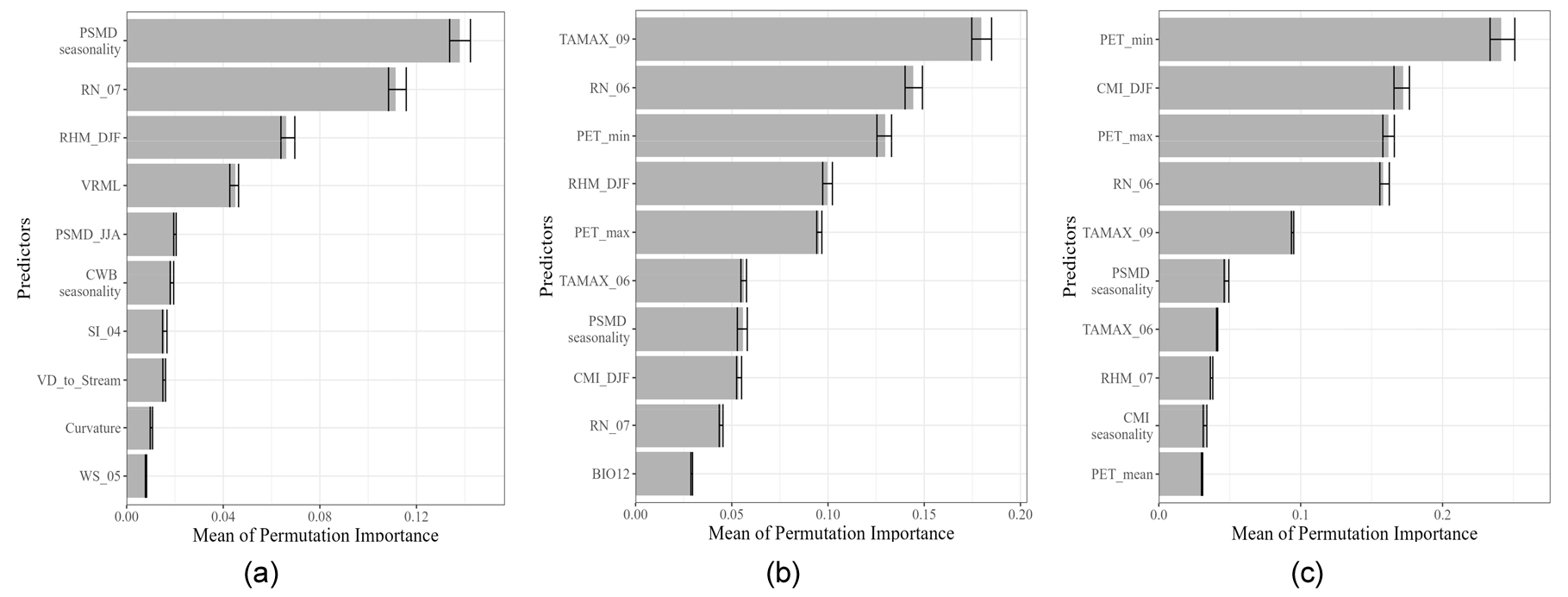
Fig. 9.
Bar graphs depicting the top 10 permutation importance values for current potential habitat prediction results in Experiment 1: (a) EXP 1-1, (b) EXP 1-2, and (c) EXP 1-3. The abbreviations for each predictor are as follows: Potential soil moisture deficit (PSMD); mean monthly precipitation (RN); relative humidity mean (RHM); December, January, February (DJF); local vector ruggedness measure (VRML); climatic water balance (CWB); solar irradiation (SI); vertical distance to channel network (VD); wind speed (WS); average of maximum temperature (TAMAX); potential evapotranspiration (PET); climatic moisture index (CMI); precipitation seasonality (BIO12).
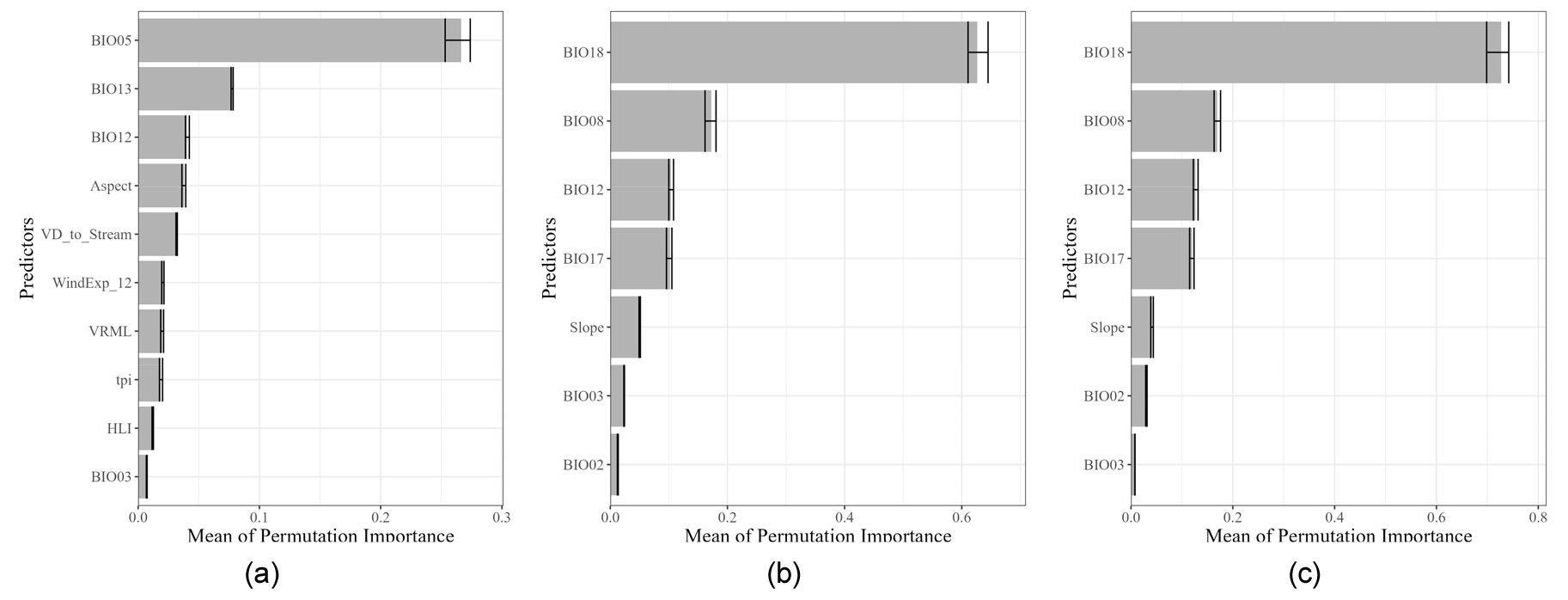
Fig. 10.
Bar graphs depicting the permutation importance values for current potential habitat prediction results in Experiment 2: (a) EXP 2-1, (b) EXP 2-2, and (c) EXP 2-3. The abbreviations for each predictor are as follows: Min temperature of coldest month (BIO05); precipitation of wettest month (BIO13); precipitation seasonality (BIO12); vertical distance to channel network (VD); wind exposure index by main wind direction (WindEXP); local vector ruggedness measure (VRML); topological position index (tpi); heat load index (HLI); temperature seasonality (BIO03); precipitation of driest quarter (BIO18); mean temperature of driest quarter (BIO08); precipitation of coldest quarter (BIO17); isothermality (BIO02).
4. 결 론
최근 기후변화 적응 정책 지원의 목적으로 종분포모델의 결과가 다양하게 이용되고 있다. 종분포모델의 입력자료는 19가지 생물기후변수 중에서 선택하여 이용하는데, 이는 기온과 강수량만을 언급하기 때문에 생물의 분포에 영향을 미치는 다양한 환경요소(예, 토양수분 등)을 대변하는데 한계가 있다. 더욱이 생리생태학적 연구가 진행되지 않은 종이라면, 연구자의 주관에 따라 환경요소 선택하여 구축된 모델은 해당 종의 분포와 관련성이 적절히 고려되었는지 알 수 없기에 그의 결과를 신뢰하기 어렵다. 빅데이터와 인공지능에 대한 관심이 최근 늘어나면서, 모델 구축을 위한 설명변수를 객관적으로 선택하는데 도움을 주는 변수선택방법이 다양하게 개발되고 있다. 변수선택방법을 통해 구축한 종분포모델을 탐색적 데이터 분석 단계에서 이용한다면, 생리생태학적 연구가 미흡한 생물종에 대하여 큰 도움이 될 것으로 보이나, 그러한 연구는 많지 않았다. 그러므로 본 연구에서는 다양한 변수선택방법을 적용한 모델이 신뢰성 있는 모델을 생성하는지, 그리고 그 결과로서 선출된 중요한 변수들이 실제 생물종의 생리생태학적 과정에 중요한 인자인지 확인함으로서 활용가능성을 평가하고자 하였다. 특히 변수선택방법을 기존의 생물기후변수뿐만 아니라 생물과 관련된 기후빅데이터에 적용하였을 때를 비교하여, 탐색적 데이터 분석 관점에서 종분포모델을 이용할 때, 19가지 생물기후변수로 충분한지를 확인하고자 하였다.
이를 위하여 실험1은 기후빅데이터를, 실험2는 19가지 생물기후변수를 이용하여 3가지 변수선택방법을 적용하였으며, 이를 통해 구축된 모델의 정확도, 구상나무의 잠재서식지 분포, 변수중요도의 결과를 비교하였다. 그 결과, 첫 번째로 모델의 정확도의 경우, 대부분의 모델이 높은 정확도를 보였다. 그러나 기후빅데이터를 이용한 모델들이 19가지 생물기후변수를 이용한 모델들에 비해 대체로 높은 TSS 값을 보여, 훈련된 모델의 정확도가 조금 더 높았다. 둘째, 모델이 예측한 구상나무의 잠재서식지를 보았을 때, 두 실험의 모델들 모두 구상나무의 대규모 서식지로 알려진 지리산과 한라산에 높은 출현확률을 보였다. 그러나 실험1에서 두 지역의 출현확률이 실험2보다 높았으며, 실험1에서는 예측하지 못했으나 자생지로 알려진 속리산에서 구상나무 출현을 높게 예측하였다. 그러므로 기후빅데이터를 이용하였을 때가 생물기후변수를 이용했을 때보다 공간적 분포를 예측하는데 현실에 더 가깝게 모의하고 있는 것으로 보인다. 세 번째로, 변수의 중요도를 살펴보았을 때, 실험1과 실험2는 구상나무의 생리생태학적 과정에 중요한 여름철 기온과 수분수지를 나타내는 변수가 중요하게 나타났다. 특히 실험1에서는 구상나무의 분포와 관련하여 중요하게 다루어지고 있는 적설과 봄철 수분 스트레스에 관한 과정을 해석할 수 있을 변수들이 선출되었다.
본 연구는 미지의 생물종의 분포에 영향을 미치는 변수를 탐색할 수 있는 종분포모델의 활용성을 보여주었다는 점에 의의가 있으나, 다음의 방법론적 한계를 지니고 있다. 첫번째로, 변수선택방법을 3가지만 사용하였다는 것이다. Brun et al.(2020)의 연구에 따르면, 종분포모델에 관한 125개의 선행연구 중 다중공선성 검증 도구로서 피어슨 상관분석계수가 가장 많이 이용되었다고 조사되었으나, VIF (Variance inflation factor) 또한 활발히 이용되고 있다. 이뿐만 아니라, Boruta (Kursa et al. 2010), Fast Correlation Based Filter (Yu and Liu et al. 2003), ReliefF (Urbanowicz et al. 2018) 등 다양한 변수선택방법이 개발되고 있다. 향후에는 이러한 최신의 기법을 사용한 결과와도 비교가 필요할 것이다.
두번째로, 본 연구에서는 입력변수 후보군의 수와 변수선택방법만을 변경하면서 결과를 서술하였으나, 모델의 결과는 주로 파라미터의 불확실성, 모델 불확실성, 미래 기후 조건의 불확실성에 의해 영향을 받는다는 것이다(Koo et al. 2017b). 일례로, 어떤 알고리즘을 사용하는지, 그 알고리즘의 파라미터(예, randomforest 알고리즘의 tree의 수) 등을 어떻게 설정하는지, 비출현지점을 어떻게 설정할것이며 몇 개를 설정할 것인지에 따라 모델의 정확도가 달라질 수 있다. 차후의 연구에서는 이러한 모델 구축과정에서의 불확실성을 복합적으로 고려한 연구 방법론이 설계되어야 한다.
마지막으로, 본 연구에서는 대상 종을 구상나무로만 진행하였다는 것이다. 본 연구에서 제시한 방법론이 종의 출현자료와 기후빅데이터를 사용하였을 때 실제로 중요하다고 생각되었던 변수가 동일하게 선택되는 것을 검증하기 위해, 생태학적인 정보가 충분한 구상나무를 대상으로 하였다. 그러나, 초본류나 관목성 식물 등 다양한 서식환경의 종들을 대상으로 위와 같은 분석이 효과적일지 추가적인 검증이 필요하다.
이러한 한계가 있음에도, 본 연구의 결과는 생태학적인 정보가 불충분한 종에 대하여 심도 있는 실험과 연구를 설계하기 전에 종의 출현자료와 기후빅데이터를 이용하여 해당 종과 연관성이 있을 만한 환경변수를 찾아내 생태생리학적 과정을 발견할 수 있는 가능성을 제공한다는 점에서 의의가 있다.
