

1. 서 론
2. 연구 방법
2.1 합성곱 및 U-Net 구성 이론
3. 연구 결과 및 고찰
3.1 모델의 구성 및 이미지 활용
3.2 균열 이미지 학습 결과
3.3 모델의 검출 결과
4. 결 론
1. 서 론
기후변화로 인해 홍수와 같은 자연재해가 자주 발생하면서 하천상의 수자원시설의 안전이 위협을 받고 있다. 특히 국내 수자원시설들은 설계 수명이 다가오고 있으며, 일부 시설은 이미 노후화 단계에 접어들어 유지 관리가 필요한 상황이므로 주기적인 평가를 통해 수자원시설의 안전성을 정확히 평가하는 기술이 필요한 시점이다. 홍수로 인해 발생할 수 있는 댐의 균열손상은 구조적 강도를 위협하고, 댐 안정성을 약화시킬 수 있기 때문에 안전성을 보장하기 위해서는 체계적인 손상 감지가 수행되어야 한다. 기존에는 수자원 시설물의 손상 판단을 위해 인력이 직접 감지를 수행하였으나 이러한 방식은 노동 집약적이고 비용이 많이 소요되는 실정이다. 이러한 상황에서 컴퓨터 공학분야 중 AI 기술의 발달로 딥러닝을 활용한 이미지 분석을 통한 손상 분석이 안전성 평가에 점차적으로 활용되고 있다.
최근 몇 년간 딥러닝은 이미지 인식 분야에서 혁신적인 발전을 이루어 왔으며, 이는 다양한 응용 분야에서 높은 사물 인식 정확도를 달성하는 데 기여하고 있다(LeCun et al. 2015). 특히 딥러닝은 기존 이미지 기반 감지 방법에 비하여 다양한 손상 형태의 특징을 검출할 수 있게 되어 구조물에서 발생할 수 있는 결함에 대한 감지 성능을 높였다. 이 같은 딥러닝은 수많은 이미지 및 영상 데이터를 기반으로 한 훈련을 통해 합성곱 신경망(CNN, Convolutional Neural Network)의 이론을 기반으로 이미지의 공간적 및 시각적 특징을 효과적으로 학습하여 이미지 분류 및 객체 탐지 분야에서 탁월한 성능을 보이고 있다(Krizhevsky et al. 2012).
딥러닝 기법은 복잡한 패턴 인식이 필요한 이미지내의 균열 탐지 영역에서도 주목을 받고 있다. 수자원 시설물의 손상 분류 중 균열에 적합한 이미지 분석 방식을 분석하였으며, 그 중 의미 기반 분할에 강점을 가지는 딥러닝 모델을 검토하였다. 이미지 분류 분야에서 의미 기반 분할은 시맨틱 세그멘테이션으로도 알려져 있으며, 이미지를 픽셀 단위로 분류하여 각 픽셀을 특정 분류 기준에 할당하는 기법이다(Tomaszkiewicz and Owerko 2023). 균열 탐지의 경우 픽셀을 “균열” 또는 “비균열”로 분류하는 작업이 이에 해당된다. 이 같은 픽셀 단위의 구분을 위해 사용되는 의미론적 분할 기법 중 의료 영상의 분할을 위해 개발된 U-Net 모델이 이를 효율적으로 처리할 수 있었다(Ronneberger et al. 2015). 이 모델에서 제시된 인코더-디코더 구조와 스킵 연결은 이미지의 세부 정보를 보존하면서도 특징을 추출하는 데 유리하여 균열 탐지 분야에서도 우수한 성능을 보이고 있다.
이후 연구에는 표면의 균열을 탐지하기 위해 합성곱 기반의 딥러닝 모델이 개발되었고, 대규모 이미지 데이터셋을 활용하여 모델의 학습을 수행하고 효율을 높여 딥러닝 기반 접근법이 균열 탐지에 효과적임을 보여주었다(Zhang et al. 2016). 분류 라벨이 지정된 이미지의 대규모 데이터 세트인 ImageNet으로 학습된 다양한 CNN 기반 모델의 건물 균열 탐지 성능이 비교 분석되어 소량의 사전 분류된 데이터로도 높은 성능을 달성할 수 있음을 보여주었으며, 딥러닝 모델의 실용성을 높이고, 실제 현장에서의 적용 가능성을 확대하였다(Ozgenel and Sorguc 2018, Matarneh et al. 2024).
딥러닝 기반의 다양한 이미지 처리 기법은 균열 탐지 외에도 구조물의 손상 평가, 유지보수 계획 수립 등에 활용되고 있으며 딥러닝을 이용하여 건물 외벽의 손상을 자동으로 분류하고 평가하는 시스템도 개발되었다(Bao et al. 2019, Cha et al. 2024). 딥러닝 계열에서 피처 피라미드 네트워크와 계층적 부스팅 기법을 결합하여 다양한 규모의 균열을 효과적으로 탐지하는 연구도 진행되었다(Lin et al. 2017, Yang et al. 2019). 또한 U-Net 모델은 중요한 부분에 집중할 수 있도록 하여 균열탐지에서 복잡한 배경을 구분할 수 있는 기능을 활용한 경우 균열의 미세한 특징을 더욱 정확하게 추출할 수 있어, 전체적인 탐지 성능을 향상시키는 것이 확인되었다(Fan et al. 2021). 이러한 기술들은 균열의 형태와 크기가 다양할 때도 높은 성능을 유지할 수 있게 해주며 딥러닝이 구조물의 유지보수 효율성을 향상시키는 데 기여할 수 있음을 보여준다.
종합적으로, 합성곱을 기반으로 한 딥러닝 모델은 이미지 인식과 균열 탐지 분야에서 중요한 역할을 하고 있다. 이러한 기술들을 종합적으로 활용하여 균열 탐지 모델을 개발하는 것은 향후 수자원시설 관리 분야에 효율적으로 작용할 것이다. 특히 U-Net은 픽셀별로 정확한 경계 검출이 필요한 균열 탐지 작업에 적합하기 때문에 본 연구에서는 이를 활용하여 수자원시설에 적용할 수 있는 이미지 분석을 통한 균열 탐지 기법의 개발 및 적용을 목표로 하고자 한다.
2. 연구 방법
2.1 합성곱 및 U-Net 구성 이론
본 연구에서는 시설물 손상 분류 중 균열에 집중하면서 기존 이미지 분석기술 현황을 조사하고 딥러닝 모델의 활용을 검토하였다. 합성곱의 기본 이론은 1980년대에 처음 제안되었으며(Fukushima 1980), 이후 합성곱 신경망이 개발된 이후(LeCun et al. 1998), 이미지나 영상 데이터의 패턴 인식에 특화된 딥러닝 모델이 개발되었다(Krizhevsky et al. 2012). 합성곱 기반의 딥러닝은 이미지의 공간적 구조를 고려하여 지역적인 특징을 추출하고, 이를 계층적으로 학습함으로써 복잡한 패턴을 인식할 수 있다. 딥러닝에서 사용되는 기본 구조 중에는 합성곱 층, 활성화 함수, 풀링 층, 그리고 완전 연결 층이 있다. 합성곱 층은 필터를 이용하여 입력 이미지의 지역적인 특징을 추출하고, 활성화 함수는 비선형성을 도입하여 모델의 표현력을 향상시킨다. 풀링층은 공간적 차원을 축소하여 계산 효율성을 높이고, 과적합을 방지한다. 마지막으로 완전 연결 층은 추출된 특징을 기반으로 최종 분류나 회귀를 수행한다. 이러한 구조는 이미지의 저차원 특징부터 고차원 특징까지 계층적으로 학습할 수 있도록 설계되어 있다. 이러한 특성으로 인하여 합성곱은 이미지 분류, 객체 탐지, 세그멘테이션 등 다양한 컴퓨터 비전 분야에서 자주 활용된다.
본 연구에서 필요한 균열 탐지에는 균열이 있는 픽셀을 탐지하고 분류하는 것이 포함되므로 의미론적 분할에 효율적인 모델이 필요하였다. 따라서 본래 생물의학 영상의 상세한 분할을 위해 개발된 U-Net 딥러닝 모델을 사용하였다. 이 딥러닝 모델은 이미지를 여러 개로 분할한 후, 분할되는 이미지들의 패턴을 분석하여 분류 결과를 도출한다. 이 경우 이미지 왜곡이 존재하여도 부분적인 특징을 추출하고 복잡한 형태를 학습하여 분류하기 때문에 성능이 높다. 기존의 합성곱 신경망의 경우, 이미지 분류를 위해 마지막에 완전 연결 레이어를 사용하지만, U-Net의 경우 전체 네트워크가 합성곱 레이어로 구성된 이미지 처리 기술로, 네트워크가 다양한 크기를 수용할 수 있어 픽셀 단위의 의미론적 분할에 더 적합하다. 왜곡된 이미지에서도 이 방법은 부분적 특징을 추출하고 복잡한 모양을 각 픽셀로 학습하여 분류하기 때문에 높은 검출 성능을 보인다.
U-Net의 구조는 Fig. 1과 같은 U자 모양의 대칭 인코더-디코더 구조를 가지고 있다. 인코더 부분은 일반적인 CNN 모델과 유사하게 입력 이미지의 특징을 추출하며, 해상도를 점진적으로 축소한다. 디코더 부분은 인코더에서 추출한 특징 맵을 이용하여 해상도를 복원하고, 최종적으로 분할 맵을 생성한다. 이 과정에서 스킵 연결을 통해 인코더의 특징 맵을 디코더로 전달하여 세부 정보를 보존한다. 인코더에서 추출된 저해상도 특징 맵과 디코더의 고해상도 특징 맵을 결합함으로써 위치 정보와 맥락 정보를 동시에 활용할 수 있다. 이는 정확한 경계 검출이 필요한 의미론적 분할 작업에서 특히 유용하다. 이 구조는 이미지 특징을 추출하는 프로세스를 효율적으로 수행하고 이 구조를 기반으로 원본 이미지와 동일한 크기의 분할 맵을 생성하여 픽셀 구분에 적합하다. 또한, U-Net은 비교적 적은 수의 학습 파라미터로도 높은 성능을 달성할 수 있어, 데이터가 제한적인 상황에서도 효과적으로 활용될 수 있다.
U-Net은 균열 탐지 분야에서 다양한 방식으로 응용되고 있으며 특히 이미지 분류 및 객체 탐지에 강점을 보이며, 균열 여부를 판별하거나 균열의 위치를 탐지하는 데 활용될 수 있다. 본 모델은 의미론적 분할에 특화되어 있어 균열의 형태와 크기를 정확하게 분할하고, 상세한 손상 분석을 가능하게 한다. 추가적으로 본 모델은 데이터의 특성과 목적에 따라 다른 모델들과 같이 선택적으로 적용되거나 결합하여 사용될 수 있다. 본 연구 대상 목표는 구조물의 노후화로 인해 발생하는 큰 노이즈와 복잡한 배경이 포함된 표면이 균열부분과 같이 있는 점이 특징이다. 이러한 문제를 극복하기 위해 딥러닝 기반의 U-Net을 활용하여 픽셀 단위로 특징을 추출하는 의미론적 분할의 균열 감지 수행이 요구된다. 기존 참고문헌 및 인터넷을 통한 균열 자료 취득 및 수자원 시설 균열 자료 취득을 수행 후, 다양한 이미지를 학습하면서 필터를 통해 합성곱 연산을 수행하고 이미지 중 균열에 해당하는 픽셀객체의 특징을 감지하고 형태를 추정하도록 하였다. 균열의 픽셀 수준 분할을 달성하고 높은 정확도와 효율성으로 이미지의 균열 검출을 수행하였다.
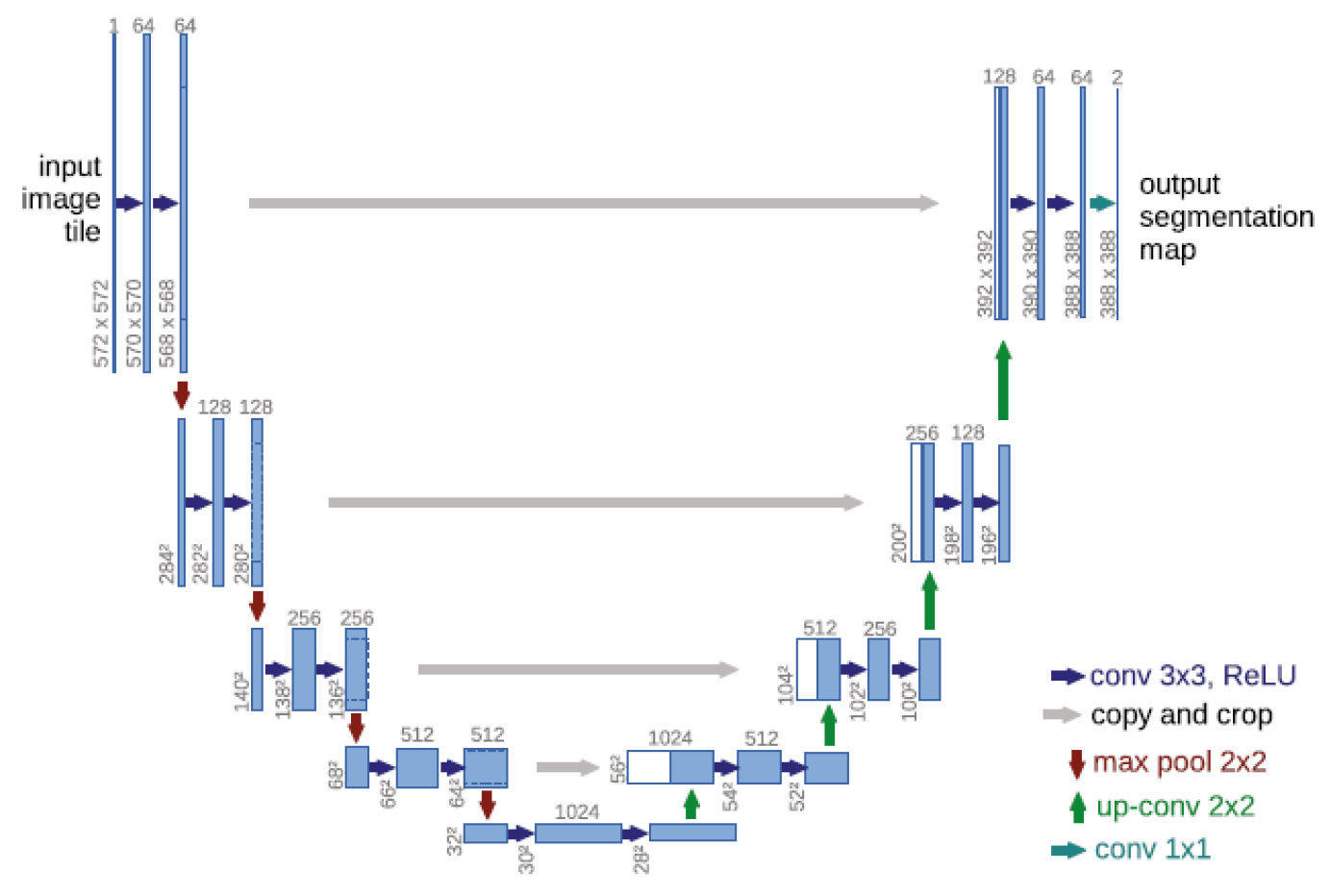
3. 연구 결과 및 고찰
3.1 모델의 구성 및 이미지 활용
본 연구에서 활용되는 딥러닝 모델인 U-Net 구성 시에는 반복적인 컨볼루션 레이어와 풀링 레이어로 구성하였으며, 각 단계에서 이미지의 공간적 차원을 축소하면서 특징 맵 생성이 가능하도록 하였다. 인코더 단계에서는 두 번의 3×3 컨볼루션 레이어와 그 뒤를 따르는 활성화 함수로 구성된 블록으로 이루어져 있으며 이러한 블록이 반복될수록 필터의 수는 두 배로 증가하여, 64, 128, 256, 512, 1024개의 필터를 사용하도록 하였다. 활성화 함수로는 ReLU (Rectified Linear Unit)를 사용하였으며, 이는 딥러닝에서 널리 사용되는 비선형 활성화 함수 중 하나로 입력값이 0보다 클 때는 그대로 출력하고, 0 이하일 때는 0을 출력하는 간단한 형태를 가지고 있다. 기존 합성곱에서 제시된 문제인 기울기 소실문제를 완화시킬 수 있으며, 기존에 활성화 단계에서 주로 사용되었던 시그모이드 함수와 비교했을 때, ReLU는 양수 영역에서 기울기가 일정하게 유지되어 깊은 신경망에서도 기울기 소실문제를 줄일 수 있게 되어 입력 데이터의 비선형적 특성을 포착하면서도 계산 효율성을 확보할 수 있게 되어 최근 딥러닝에서 주로 활용되고 있다.
디코더 단계의 경우 인코더에서 추출된 압축된 정보를 바탕으로 원래 이미지와 동일한 크기의 분할 맵을 복원하는 역할을 하며, 이는 반복적인 업샘플링 블록으로 구성되며, 각 블록은 2×2 업컨볼루션 레이어를 통해 공간 해상도를 두 배로 확대하였다. 최종 출력층은 1×1 합성곱 레이어로 구성되어 있으며, 이는 분류 기준 수에 맞는 채널 수로 변환되고 이어서 활성화 함수를 통해 각 픽셀의 각 분류 기준 별 확률을 계산하게 되어 각 픽셀이 어느 분류 영역에 속하는지를 예측하도록 구성하였다. U-Net 모델의 인코더-디코더 구성 시 오픈 라이브러리를 기반으로 한 Tensorflow를 활용하였으며, 이는 다양한 자료 처리시 벡터와 행렬을 일반화하여 수치 계산 및 딥러닝을 원활하게 구성하도록 하는 라이브러리로 활용되고 있어 본 모델 구축에 활용하였다.
훈련을 위한 이미지 데이터셋 구축을 위해 균열이 있는 일반 이미지 1000장과 각 이미지 중 균열이 있는 픽셀에 이를 구분하기 위한 마스크가 포함되어 있는 훈련자료를 기존 연구로부터 확보하였으며, 모델 구성 중 가중치 계산용 테스트를 위한 검증용 이미지 300장과 그에 해당하는 균열 마스크가 포함되어 있는 이미지 자료를 확보하여 이를 모델 학습에 적용하였다. 훈련 데이터를 학습하기 위한 훈련 설정으로는 학습률(Learning Rate)은 0.0001, 에포크(epoch)는 20회로 설정하고 훈련을 진행하였다. 에포크는 딥러닝 및 머신러닝 모델 훈련 과정에서 사용하는 중요한 개념 중 하나로, 훈련 데이터셋 전체를 모델에 한 번 학습시키는 과정을 의미하며, 학습 반복 횟수의 단위이다.
3.2 균열 이미지 학습 결과
U-Net 모델 구축을 위하여 학습을 수행하였으며, 그 결과는 다음과 같다. Fig. 2(a)는 U-Net 모델의 학습 과정에서 훈련 횟수가 0부터 20까지 진행됨에 따라 훈련 데이터에 대한 정확도는 지속적으로 증가함을 보여주었으며, Fig. 2(b)의 경우 훈련 횟수에 따라서 모델 손실이 감소하는 경향을 보여준다. 초기 훈련 시기에는 모델이 데이터의 특징을 학습하는 단계이기 때문에 손실 값이 높고 정확도는 낮을 수 있으나 훈련이 점차 진행되면서 모델은 점차 입력 데이터의 패턴과 구조를 이해하게 되어, 특히 훈련 횟수 10부터는 훈련 정확도가 향상되고 손실 값은 감소함을 보여주었다. 검증 데이터에 대한 정확도와 손실 또한 훈련 횟수 증가에 따라 개선되는 추세를 보이지만, 검증 손실과 정확도는 훈련 데이터에 비해 변동성이 클 수 있으며, 이는 모델이 새로운 데이터에 얼마나 일반화되는지를 나타낸다. Fig. 2(b)의 손실 그래프의 경우 손실이 점진적으로 감소하여 모델의 일반화 성능이 적합함을 나타냈다. 전체적으로 본 균열 이미지 활용 U-Net모델의 학습 과정의 경우 훈련횟수 0부터 20까지 검증 정확도가 비교적 일관되게 상승하고 손실이 감소하여, 모델이 과적합 없이 전체적인 성능 향상을 이루고 있음을 의미하였다.
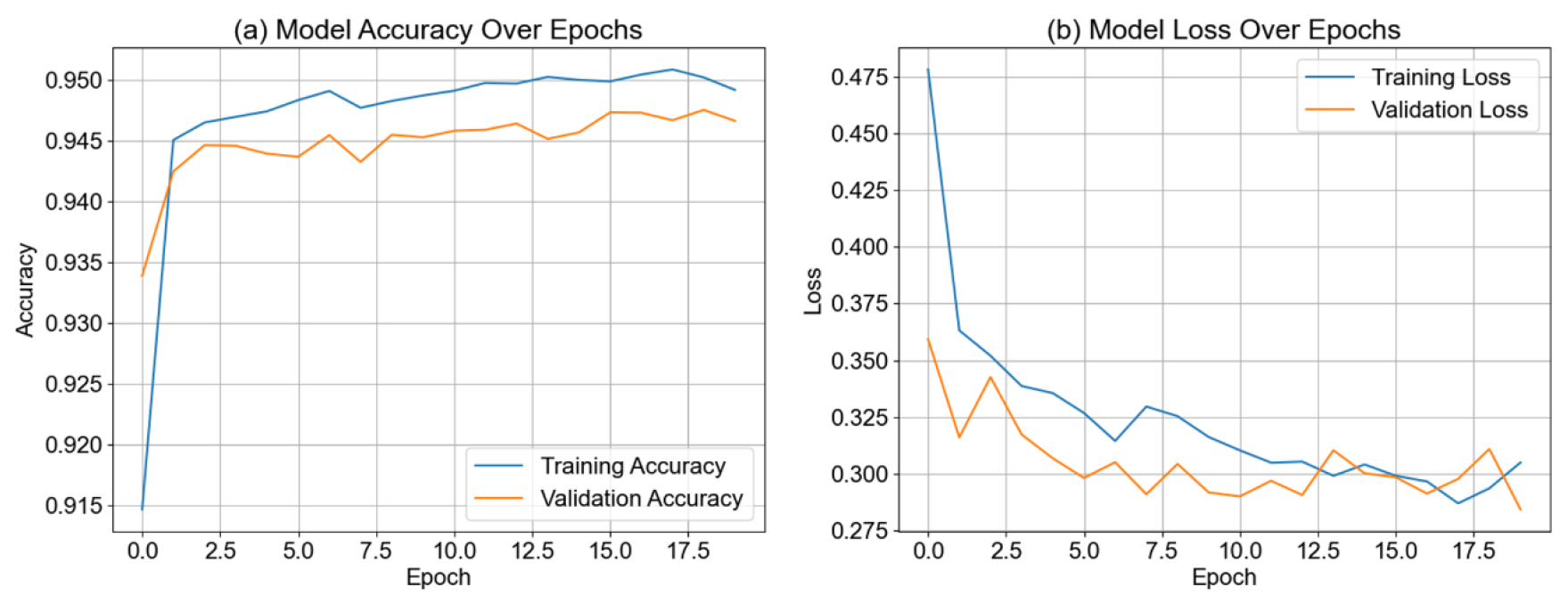
Fig. 3은 균열 검출을 위한 U-Net 모델의 첫 번째 합성곱 계층에서 학습된 커널의 가중치를 보여준다. 각 작은 사각형 또는 필터는 모델이 입력 이미지에서 추출하는 특징들을 나타내며, 이러한 특징들은 모델이 균열의 형태와 패턴을 인식할 수 있도록 한다. 커널 가중치의 시각화는 모델이 어떤 특징에 집중하고 있는지 이해하는 데 유용하다. 이러한 필터들은 균열의 경계, 방향성, 질감 등을 감지하도록 학습되며, 이를 통해 모델은 이미지 내에서 균열을 정확하게 분할하고 식별할 수 있게 된다.

Fig. 4의 경우 균열 탐지를 위한 U-Net 모델의 첫 번째 합성곱 블록에서 위 가중치를 이용하여 생성된 활성화 맵(activation map)을 보여준다. 각 작은 이미지는 입력 이미지에 적용된 하나의 필터의 출력을 나타내며, 균열과 관련된 가장자리, 질감 또는 패턴 등의 다양한 특징을 강조한다. 활성화 맵을 시각화하여 본 U-Net 모델이 입력 이미지를 초기 단계에서 어떻게 해석하고 처리하는지 확인할 수 있었다. 본 활성화 맵은 첫 번째 블록으로 주로 저수준의 특징을 포착하며, 이러한 활성화를 관찰하면 모델의 필터가 입력 이미지에서 어떤 부분을 중점적으로 분석하는지 알 수 있어, 균열의 정확한 탐지와 분할에 초점을 두는 방식을 확인할 수 있다. 모델이 실제 균열이 아닌 다른 부분에 대해 강하게 반응하고 있다면 이는 모델이 잘못된 특징에 집중하고 있다는 신호일 수 있으며, 이를 통해 데이터셋의 보완이나 모델의 구조적인 수정이 필요한 것을 드러낸다. 본 모형에서는 활성화 맵의 특정 영역인 균열이 밝을수록 해당 영역에서 필터가 더 강하게 반응했다는 것을 의미하고, 이는 모델이 해당 균열 부분을 중요한 특징으로 인식하고 있음을 나타낸다.

3.3 모델의 검출 결과
학습한 균열 데이터를 활용하여 딥러닝 모델을 구축한 이후 이미지에 대한 균열 검출을 수행하였다. 확보한 균열 이미지 데이터 중 학습에 활용되지 않는 데이터를 통한 균열 검출 검증 및 비교를 수행하였다. 본 모델은 균열 이미지를 사용하여 네트워크에서 합성곱을 통해 가중치 맵을 훈련하고 수정할 수 있으므로, 이미지의 균열에 해당하는 픽셀 객체의 특성을 Fig. 5와 같이 감지할 수 있게 되었다. 이는 균열 데이터를 대상으로 모델을 활용하여 균열 검출을 수행한 결과를 보여준다. 각 이미지의 윗부분은 균열이 있는 콘크리트 표면의 원본 사진으로, 이는 딥러닝 모델의 입력 데이터로 활용되었으며, 아래부분은 원본 이미지 위에 초록색 영역으로 모델이 예측한 균열의 위치를 시각화한 결과를 나타낸다. 결과적으로 모델이 입력 이미지를 기반으로 균열의 픽셀을 비교적 정확히 분류한 결과를 보여주었다. 그러나 어둡거나 균열이 불명확한 이미지 데이터의 경우 검출에 다소 부정확한 결과가 나타났다. 전반적으로 학습된 모델은 대체적으로 균열을 감지한 것으로 보였으나 모델의 성능을 더 정확히 평가하려면 정량적인 평가 지표의 활용이 필요하다.

학습 및 적용 결과, 실제 이미지와 분류된 결과를 비교하면서 참/거짓 구분을 통하여 각 픽셀별 분류의 정확도을 분석하였다. TP는 균열 이미지가 정확하게 분류된 경우를 의미하고, TN은 비균열 이미지가 정확하게 분류된 경우를 나타낸다. 반면, FP는 비균열 이미지가 잘못 분류된 경우, FN은 균열 이미지가 잘못 분류된 경우를 의미하며 이러한 정의는 Table 1에 정리하였다. 이후 검출 성능을 정량적으로 평가하기 위해 기존 문헌에서 활용되는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall) 등의 지표를 적용하였다(Zhang et al. 2016, Fan et al. 2021, Cha et al. 2024). 각 정량지표는 공식이 다음과 같다.
정확도는 전체 픽셀 중 균열로 분류된 참값과 비균열로 분류된 참값의 비중을 계산하는 방식으로 적용방식이 간단하며 직관적인 장점을 가지고 있으나, 본 연구의 적용 사례와 같이 특정 분류 개체(균열) 영역이 다른 분류 개체(비균열) 영역보다 비율이 상당히 차이가 나는 경우 모형의 성능을 제대로 반영하지 못할 수도 있다. 정밀도는 이미지에서 모델이 균열로 판단한 모든 영역 중 실제 구조물의 균열을 정확히 탐지한 비율을 의미하며, 재현율은 실제 구조물의 균열 부위 중 모델이 균열로 올바르게 탐지한 비율을 뜻한다. 높은 정밀도는 인공신경망의 오류율이 낮음을 나타내고, 높은 재현율은 구조물 내의 균열 중에서 인공신경망이 놓친 부분이 적다는 의미이다. 정밀도의 경우 검출되는 균열 픽셀의 신뢰성 여부가 중요하고 비균열 이미지가 잘못 분류된 경우인 FP를 최소화해야 되는 상황에서 강점을 보이나, FN을 고려하지 않기 때문에 모델이 놓친 균열 부분은 평가하지 못하는 단점이 있다. 재현율은 감지되지 않는 손상이 위험할 경우에 이를 쉽게 파악할 수 있는 장점을 가지고 있어 안전 및 유지관리 분야 적용에 유리하며, 단점으로는 FP를 고려하지 않기 때문에 모델이 재현율에 중점을 둘 경우 균열이 아닌 곳을 균열로 평가하게 될 수도 있다.
제시된 방식을 활용하여 10개의 이미지에 대한 균열픽셀 산출 결과 및 평균을 정량적으로 평가한 내용을 Table 2에 표기하여 모델의 성능을 다각적으로 분석하였다. 먼저, 정확도는 모델이 전체적으로 얼마나 잘 맞추었는지를 나타내는 지표로, 모든 이미지에서 높은 수치를 기록했다. 정확도는 91.77%에서 99.27% 사이에 분포하며, 평균 정확도는 97.68%로 우수한 결과를 보여주었으나, 전체 이미지 중 균열이 차지하는 비중이 낮을 수도 있어서 이러한 결과가 드러났다고도 볼 수 있다. 정밀도는 모델이 탐지한 균열 중 실제로 균열인 비율을 나타냈으며 평균 정밀도는 78.47%로 정확도 보다는 낮은 값을 보였으며, 이미지별 편차가 다소 크게 나타났다. 특히 (e)에서는 정밀도가 49.51%로 낮아 모델이 미세한 균열 영역의 경우 검출이 잘 안되었음을 보여준다. 재현율은 실제 균열 중에서 모델이 얼마나 잘 탐지했는지를 평가하는 지표로 평균 재현율은 82.26%로 정밀도보다는 높은 경향을 보이며, 대부분의 이미지에서 모델이 실제 균열을 잘 탐지했음을 보여주었다. 하지만 (j)에서는 재현율이 42.17%로 낮게 나타나 어두운 이미지의 경우 실제 균열을 놓친 경우가 확인되었다. 전체적으로 분류 비교 결과 TP (True positive)의 비율이 높아 일부 균열 및 손상 객체 분류에 성공하였으나, 일부 이미지에 대해서는 미검출 영역 FN (False negative)이 상대적으로 높게 나타났다. 이 결과를 통해 본 학습 모델은 정량적으로도 높은 적용성을 보여주는 것을 확인하였으나, 특정 상황에서의 검출 오류를 개선해야 되는 부분이 필요함을 알 수 있었다.
Table 1.
Confusion matrix of actual and predicted image
| Confusion matrix | Actual image type | ||
| Positive crack | Negative crack | ||
| Predicted image type | Positive crack | True Positive (TP) | False Positive (FP) |
| Negative crack | False Negative (FN) | True Negative (TN) | |
Table 2.
Image detection performance measures using accuracy, precision and sensitivity
Fig. 6에서 제시된 이미지는 본 딥러닝 기반의 모델을 활용하여 기존 참고문헌에서 활용된 수자원 시설물 중 중국 라오닝 성/양쯔강 지류의 댐 구조물의 이미지로부터 균열을 탐지한 결과를 보여준다(Feng et al. 2020, Huang et al. 2023). 상단 이미지는 균열 탐지 전과 후를 비교한 모습으로, 왼쪽의 원본 이미지에서는 콘크리트 표면의 균열이 육안으로 관찰 가능하지만 얇은 형태의 균열이며, 오른쪽에서는 모델이 초록색 선을 사용하여 균열의 위치와 형태를 정확히 탐지한 결과를 볼 수 있다. 하단 이미지는 댐 표면에서의 균열 탐지 결과를 나타내며, 모델이 얇고 불규칙적인 균열, 교차된 균열, 거친 텍스처 위의 균열 등 여러 유형의 구조물을 정확히 감지한 것을 확인할 수 있었다. 다만, 표면이 지나치게 복잡하거나 조도가 높은 경우 FP나 FN이 발생할 가능성이 있으므로 추가적인 후처리와 모델 개선이 필요할 수 있다. 결론적으로, U-Net 기반의 픽셀 단위 균열 검출 기술은 수자원 구조물의 균열 감지에 활용될 수 있는 도구의 가능성을 보여주었으며, 이를 통해 향후 유지보수의 효율성을 크게 향상시킬 수 있을 것으로 판단된다.

4. 결 론
본 연구에서 훈련된 U-Net 딥러닝 모델은 균열 탐지를 위해 훈련된 데이터를 활용하여 이미지에서의 균열을 효과적으로 식별하도록 하였다. 이 모델은 합성곱을 기반으로 하며, U자 형태의 네트워크로 구성되어 있어 이를 통해 픽셀 단위의 의미론적 분할로 정밀한 균열 탐지가 가능해진다. 합성곱은 딥러닝에서 중요한 역할로 입력 이미지에 커널 가중치를 적용하여 특징을 추출한다. 커널 가중치는 학습 과정에서 최적화되며, 다양한 크기와 방향의 균열 패턴을 인식하는 데 도움을 준다. 활성화 맵은 이러한 과정에서 특정 특징에 대한 모델의 반응을 시각화한 것으로, 모델이 이미지의 어느 부분에 주목하고 있는지를 보여준다.
모델을 훈련하고 성능을 비교하기 위해, 훈련 데이터 1000장과 검증 데이터 300장으로 학습을 진행하였다. 훈련된 네트워크로부터 검증 데이터를 균열 이미지와 비균열 이미지로 분류하고, 정량지표 계산을 위해 각 이미지 및 균열 분류 이미지로부터 TN, TP, FP, FN을 산출하였으며 성능지표인 정확도, 정밀도, 재현율을 계산하였다. 본 모델은 전반적으로 높은 정확도 및 정밀도/재현율 상 높은 성능을 보여주었으며, 균열의 위치와 형태를 효과적으로 시각화 하여 픽셀 수준 균열을 감지하는데 높은 효율성을 보여주었다. 또한 커널 가중치 및 활성화 맵의 시각화를 통해 모델이 균열의 경계, 형태, 질감 등을 효과적으로 포착하고 있음을 확인할 수 있었다. 이는 모델이 복잡한 균열 패턴도 정확히 인식할 수 있도록 하여 이미지에서의 균열 검출을 비롯하여 수자원 시설물 이미지에 대한 적용에도 확인되었다.
모델의 향후 개선점으로는 데이터 증강을 통해 다양한 환경에서의 균열 이미지를 추가로 학습시킴으로써 일반화 성능을 향상시킬 수 있는 점이다. 또한 현 모델의 단점으로는 계산 복잡도가 높아 필요시에는 실시간 처리에 부담이 될 수 있으며, 복잡한 배경이나 조명 조건에서의 균열 탐지에 한계가 있을 수 있기 때문에 필요시 실시간 검출을 위한 향후 연구 방향도 검토해 볼 수 있다. 또한 데이터 증강 외에도 전이 학습을 통한 사전 학습된 모델 활용도 고려될 수 있다. 마지막으로 설정한 학습률에 따라 같은 딥러닝 모델이라 하더라도 성능에 차이가 발생할 수 있기 때문에, 향후 학습 횟수 추가 변경 및 데이터셋의 확보로 본 기술의 정확도를 높일 수 있을 것으로 판단된다. 모델의 경량화 및 실시간 처리 능력 향상 외에도 다른 기술과의 융합을 통해 활용성이 높은 균열 탐지 시스템을 구축이 가능할 것으로 보인다. 딥러닝 모델과 전통적인 이미지 처리 기법을 결합하거나, 다양한 센서 데이터를 통합하여 복합적인 분석을 수행하는 것이 가능해지면 수자원 구조물의 안전 진단 및 평가를 위한 모니터링에서 활용도가 더욱 높아질 것으로 기대된다.
결론적으로 딥러닝 기법 중 U-Net 구조를 활용하여 균열 손상 이미지들의 학습과 특징 추출을 통하여 이미지 내에서 픽셀 단위로 일부 손상 객체를 분류해 낼 수 있었으며 이를 수공 구조물에도 적용하여 균열 검출을 할 수 있는 적용성을 확인하였다. 본 연구에서 적용되는 기법은 향후 추가적인 이미지 데이터 확보를 통해 수자원 시설물의 정기적인 손상 탐지 및 모니터링에 효율적인 방식으로 지속적으로 활용될 수 있을 것으로 판단된다.
