

1. 서 론
2. 연구 방법
2.1 모델 트리 기법
2.2 유사량 추정 모델
2.3 유사량 모델 평가 데이터
3. 연구 결과
3.1 유사량 추정을 위한 Jang et al. (2023) 모델 적용
3.2 추가 데이터를 활용한 Jang et al. (2023) 모델 개선
3.3 유사량 추정 모델의 유사량 관계식 비교
4. 결 론
1. 서 론
하천 환경에서 총 유사량을 추정하는 것은 하천 역학을 이해하고 유역의 건강성을 관리하는 데 필수적인 요소이다(Walling and Webb 1981, Asselman 2000, Horowitz 2003). 총 유사량은 유속, 수심, 하폭, 하상 경사 등과 같은 다양한 수리학적 요인에 영향을 받으며(Mulyono et al. 2021, Seo et al. 2018), 이를 정확히 추정하는 것은 효과적인 하천 관리뿐만 아니라 산사태 및 유역 유사 유출과 관련된 홍수 시나리오에서 하류 생태계 영향을 분석하는 데 활용된다(Walling and Webb 1981, Asselman 2000, Horowitz 2003, Mulyono et al. 2021). 이러한 유사량 추정을 위해 최근 대규모 데이터 세트에서 입력 변수와 출력 변수 간의 복잡한 관계를 분석하는 데 효과적인 데이터 마이닝 기반 접근 방식이 활용되고 있다(Jang 2017, Jang et al. 2023)
데이터 마이닝 기법은 무질서한 데이터를 처리하는 데 특히 능숙하여 유사량 데이터와 같은 현장 측정 데이터를 사용한 예측에 적합하다(Quinlan 1986, Wang and Witten 1996, Jang and Kang 2020, Jang et al. 2023). 대표적인 접근 방식 중 하나는 인공 신경망(Artificial Neural Network, ANN)을 사용하여 과거 유사량 데이터를 학습한 후 미래의 유사량을 예측하는 방식이다(Atieh et al. 2015, Rezaei and Vadiati 2020, Gupta et al. 2021, Rezaei et al. 2021, Cisty et al. 2021, Kang et al. 2021). 그러나 인공 신경망은 대규모 복잡한 데이터의 상관성을 쉽게 처리할 수 있는 장점에도 불구하고, 히든 레이어의 해석이 제한적이기 때문에 입력 변수가 예측에 어떤 영향을 미치는지 명확히 분석하기 어렵다는 한계가 있다(Atieh et al. 2015, Rezaei and Vadiati 2020, Gupta et al. 2021, Cisty et al. 2021). 이러한 점에서 회귀 모델 및 신경망을 포함한 머신 러닝 알고리즘은 퇴적물 운반 예측의 정확성과 효율성을 향상시키는 데 매우 유용하다는 평가를 받고 있다(Kang et al. 2022, Kang et al. 2024).
최근 연구에서는 데이터 마이닝의 해석 가능성을 강화하고 예측 정확성을 높이기 위해 모델 트리(Model Tree)와 같은 기법이 제안되었다(Jang et al. 2023). 모델 트리는 변수 간의 비선형 상호 작용을 효과적으로 처리할 수 있을 뿐만 아니라, 추정치의 의사 결정 과정을 시각적으로 이해할 수 있는 이점이 있다(Quinlan 1986, Wang and Witten 1996, Jang and Kang 2020, Jang et al. 2023). 이 중 Jang et al. (2023)의 연구는 모델 트리를 활용하여 총 유사량과 유사 이송 모델을 평가하고, 실제 데이터를 검증하여 기존 유사 이송 추정의 정확성을 개선하였다. 그러나 해당 연구는 모델의 학습 및 검증 데이터 비율에서 제한점이 있었으며, 이는 실측 데이터 활용을 통해 실질적인 활용성을 평가하는 추가 연구의 필요성을 시사한다.
본 연구는 Jang et al. (2023)의 연구를 확장하여 기존 모델 트리 기반 유사량 추정 모델을 평가하고, 신규 데이터를 추가로 트레이닝하여 모델의 예측 성능과 실측 데이터와의 비교 분석을 통해 개선점을 제시하는 것을 목적으로 한다. 이를 통해 다양한 수리학적 요인이 총 유사량 추정에 미치는 영향을 구체적으로 분석하고, 보다 정교하고 신뢰할 수 있는 모델을 제공함으로써 하천 관리와 유역 건강성 유지에 기여하고자 한다.
2. 연구 방법
2.1 모델 트리 기법
트리 기반 모델을 사용한 유사량 추정은 직접 측정 방법에 대한 비용 효율적이고 효율적인 대안을 제공할 수 있다(Breiman 2001, Jang et al. 2023). 모델 트리(Model Tree, MT), 랜덤 포레스트(Random Forest, RF), M5Prime (M5P)과 같은 트리 기반 모델은 입력 변수와 총 유사량 간의 복잡하고 비선형적인 관계를 처리할 수 있기 때문에 널리 사용되고 있다(Quinlan 1986, Wang and Witten 1996, Breiman 2001, Kang et al. 2021, Jang et al. 2023). 이러한 모델은 데이터 가용성이 제한된 지역에서 특히 유용하다. 모델 트리 접근법은 대규모 데이터 세트에서 입력 변수와 출력 변수 간의 관계를 분석하는 데이터 마이닝 기법이다. 특히 현장 측정 데이터를 사용하여 유사 유출량을 예측하는 데 효과적으로 사용된다.
모델 트리 기법은 데이터 그룹을 유사한 성격의 데이터끼리 분류하여 일정한 조건에 의해 하위그룹으로 분리해 나가는 절차를 기반으로 한다(Jang et al. 2018, Jang and Kang 2020). 모델 트리의 구조는 tree의 성장(growing)과 전지(pruning) 그리고 다듬는 작업(smoothing)으로 구성되어 있으며, Eq. 1의 표준편차감소율(Standard Deviation Reduction, SDR)이 최대치가 될 때 큰 가지에서 작은 가지로 전지된다(Quinlan 1986, Wang and Witten 1996, Kim and Suh 2013).
여기서, T는 종속변수의 전체 표본 집합이며, 는 세부 구간으로 나누어진 종속변수의 하위 표본 집합, σ는 표준편차(standard deviation), 와 는 원소의 개수로 표현되는 집합의 크기이다(Kim and Suh 2013, Jang, 2020). 각 독립변수의 그룹화 구분은 종속변수의 표준편차감소율로 판단된다. 즉, 불필요한 가지를 포함한 전체 표본 집합 T에서 표준편차 σ(T)를 계산한 후 각 독립변수 별 임의 구간에 따라 임의의 세부 구간으로 나누어진다(Jang and Kang 2020). 임의로 구분된 세부 구간 중 표준편차감소율이 가장 큰 구간을 선택하여 전지되며, 이 후 하부 tree가 성립한다(Jang and Kang 2020). 전지된 하위 그룹의 성장 및 전지조건도 똑같은 과정을 거치며, 표준편차감소율이 원하는 수치에 도달했을 경우, 혹은 그룹화 후 남은 자료의 개수가 선택한 기준보다 작아졌을 때 tree의 성장이 종료된다(Jang and Kang 2020).
2.2 유사량 추정 모델
Jang et al. (2023) 연구에서는 유사량 추정을 위한 방정식 형태의 모델을 제시하였다. Jang et al. (2023) 모델은 데이터 마이닝 기반의 모델 트리를 활용하여 유사량과 수리학적 인자 간의 복잡한 비선형 관계를 효과적으로 처리할 수 있도록 개발되었다. Eq. 2는 MT 기반으로 도출된 총 유사량 추정 모델이다. 이 모델은 간결한 수식 형태로 유사량을 추정할 수 있는 장점을 가지고 있으며, 다양한 수리 조건에서의 유사량 변화를 설명하는 데 유용한 도구로 평가되었다. Jang et al. (2023) 모델은 하천 흐름과 관련한 수심(Depth, D), 수면 또는 에너지 경사(Slope, S), 수면 폭(Width, W), 흐름 유속(Velocity, V) 및 하상토 중앙입경(Mean Bed Material, d50)을 매개변수를 활용하였다. 적용 가능한 매개변수 범위, 계수 및 지수는 Jang et al. (2023)의 논문에서 제시한 모델에 의해 결정할 수 있었으며, 해당 연구에서 모델 도출을 위해 활용된 자료의 범위는 Table 1과 같다. 도출된 최종 모델은 간단한 조건부 방법으로 결정된 계수를 가지고 있기 때문에 기존 유사 이송 방정식보다 훨씬 쉽고 간단하게 접근할 수 있다. 또한 연구의 대상 섹션에서 획득한 데이터 세트는 더 광범위한 범위를 다루기 때문에 더 많은 조건에 적용할 수 있을 것으로 예상된다.
여기서, W는 하폭(m), V는 유속(m/s), D는 평균 수심(m), S는 수면 또는 에너지 경사 (m/m), d50(mm)은 하상 재료의 중앙입경, a, b, c, d, e 및 f는 매개변수의 상수이다. 해당 모델에서 개발을 위해 사용한 데이터는 2007년에서 2020년까지 계측된 유사량 자료를 사용하였다.유사량 계측이 대유역인 한강, 낙동강, 금강, 영산강을 비롯하여 주요 하천에서 홍수 전후, 홍수 시 수행된 만큼, 최소 수면 폭은 9.46 m, 최대 수면 폭은 637.27 m 등 넓은 범위를 포괄하고 있다. 모델 트리를 활용한 유사량 추정 연구에서 활용하는 데이터의 범위가 광범위할 지라도 수많은 조건에 의해 하위 그룹을 생성한 후 최종 모델을 제시하기 때문에 범용적 사용이 가능하다는 장점이 있다. 그러나 Jang et al. (2023) 모델은 2007년부터 2020년까지의 데이터를 기반으로 개발되어 이후 데이터에 대해 적합도를 검증하지 못한 한계가 있다. 따라서 이렇듯 광범위한 범위를 포함할지라도 새로 추정하고자 하는 지점의 수리 조건이 모델링 개발 범위에 해당하는지 검토할 필요가 있다. 본 연구에서는 이미 제시된 Jang et al. (2023) 유사량 추정 모델과 함께 기존 데이터에 2021년부터 2023년까지의 데이터를 추가로 트레이닝하여 모델을 개선하였다.
Table 1.
Data range of existing sediment discharge estimation model by Jang et al. (2023)
2.3 유사량 모델 평가 데이터
본 연구에서는 2021년부터 2023년까지 관측된 자료를 활용하여 2.2의 유사량 추정 모델을 적용하여 유사량을 추정한 후 관측된 유사량과 비교하였다. 2021년부터 2023년까지의 유사량 데이터는 한국수자원조사기술원에서 발간하는 수문조사 보고서를 참고하였다(Korea Water Resources Survey Technology Institute, 2022, 2023, 2024). 활용된 데이터 수는 1,104개이며, 이 중, 2021년 데이터가 30%, 2022년과 2023년은 각각 36%와 35% 이다. 지역별로는 한강에서 28%, 낙동강에서 29%, 금강에서 21% 및 영산가에서 22%의 데이터가 수집되었다(Table 2). 수집된 2021년부터 2023년까지의 유사량 데이터 범위는 Table 3에서 확인할 수 있다. 함안군(계내리) 지점의 경우 2021년 부터 2022년까지 매년 유사량 측정이 수행되었으며, 2021년의 홍수 후 하상토 중앙입경은 0.21 mm, 2022년 0.28 mm, 2023년 0.71 mm이다.
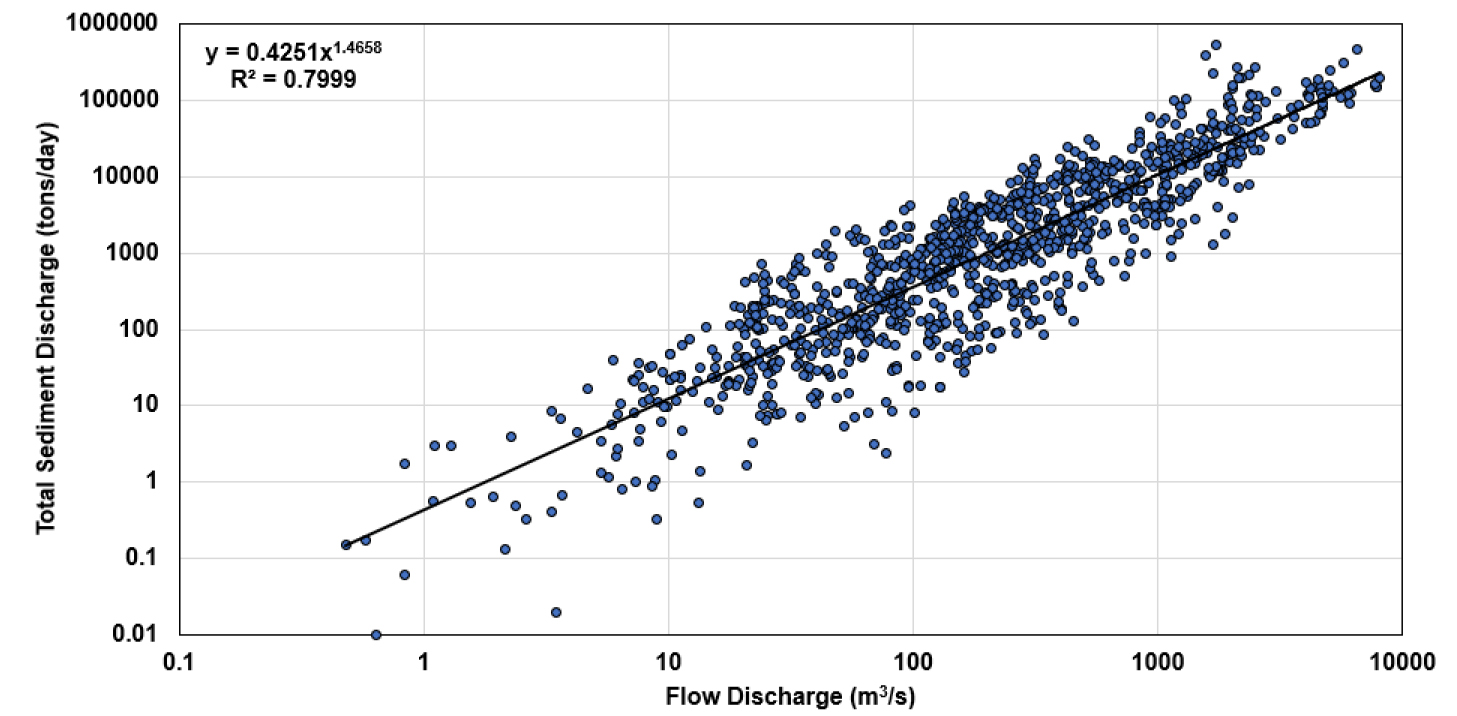
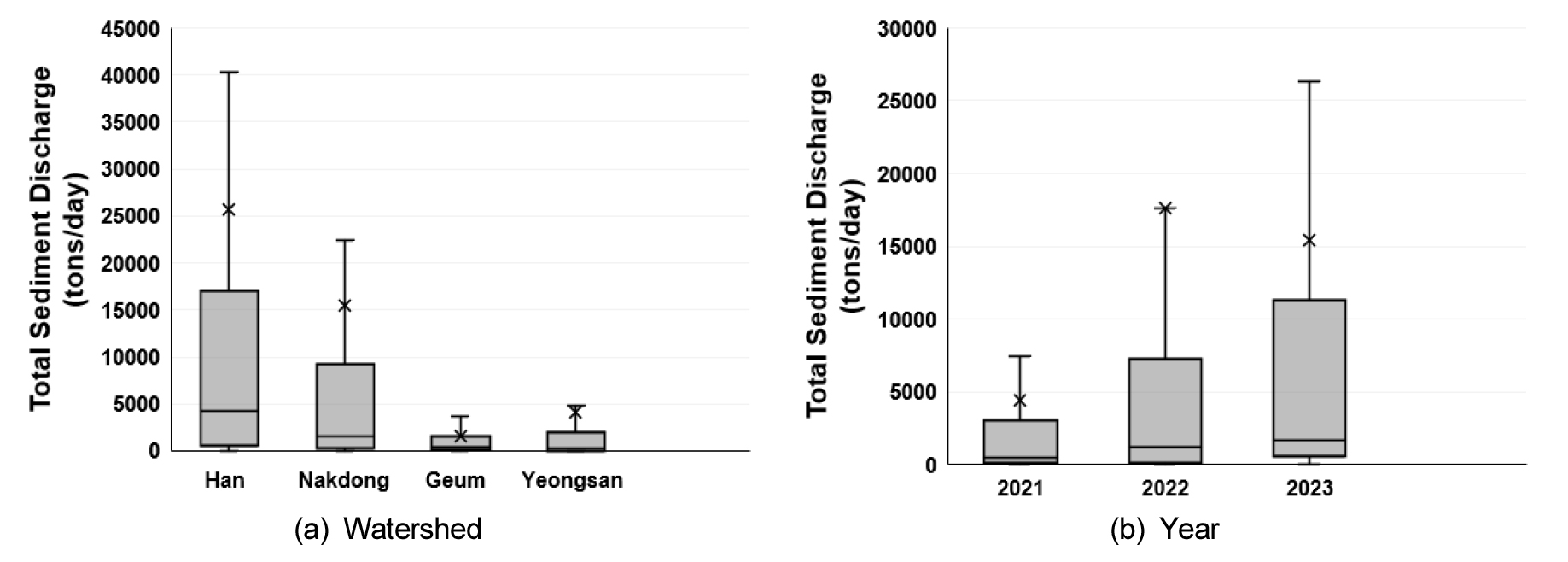
2021년부터 2023년까지 전국의 측정지점을 아우르는 유사량 관계식 도출 결과, 유량의 범위는 0.48 m3/s에서 8,099.4 m3/s인것으로 나타났다. 가장 작은 유량은 2021년 12월 14일 영산강 수계 탐진강 장흥군(예양교) 지점에서 발생한 유량이며, 가장 큰 유량은 2023년 8월 11일 낙동강 수계 본류 함안군(계내리) 지점에서 발생하였다. 관측된 자료를 활용한 유사량 관계식은 Fig. 1과 같다. 연도별 유사량 관측 결과를 보면, 평균 유사량은 2022년에 더 많이 발생하였으나, 최대값 및 중앙값은 2023년에 더 크게 발생하였음을 알 수 있다. 지역별로는 한강에서 가장 많은 유사량이 발생하였으며, 낙동강, 영산강, 금강 순인 것으로 나타났다(Fig. 2).
Table 2.
Number of sediment discharge measured from 2021 to 2023 in Korea
| 2021 | 2022 | 2023 | Sum | |
| Han | 66 | 156 | 84 | 306 |
| Nakdong | 103 | 93 | 129 | 325 |
| Geum | 75 | 78 | 82 | 235 |
| Yeongsan | 85 | 67 | 86 | 238 |
| Sum | 329 | 394 | 381 | 1,104 |
Table 3.
Data range from 2021 to 2023 for existing sediment discharge estimation model evaluation
3. 연구 결과
3.1 유사량 추정을 위한 Jang et al. (2023) 모델 적용
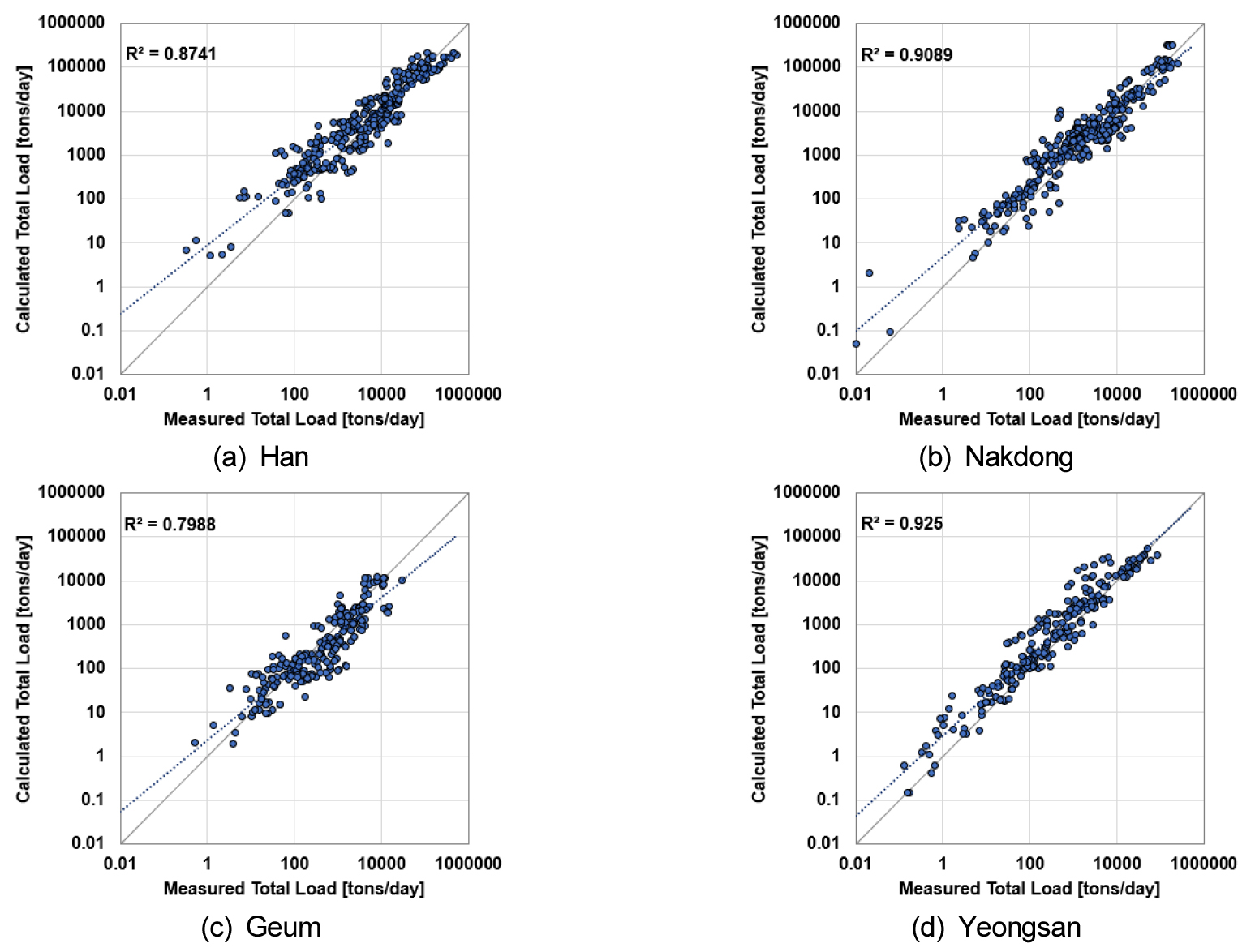
본 연구에서는 2021년부터 2023년까지 관측된 2.3절의 최신의 유사량 자료를 활용하여 2.2절에서 소개한 유사량 추정 모델을 평가하였다. 유사량 추정은 연도별 수계별로 구분하여 산정하였다(Fig. 3). 먼저 수계별 분석 결과, 전체적으로 비교적 최적 적합도에 근접한 것으로 나타났다. 낙동강의 경우 분산정도가 가장 작았으며, 유사량 100 tons/day와 10,000 tons/day 사이의 추정 정확도가 높음을 알 수 있다. 영산강의 경우 저유사량 고유사량 모두 추정 패턴이 일정한 것으로 나타났다. 한강의 경우 100 tons/day 이하의 저유사량에서의 오차가 상대적으로 크게 나타나는 것으로 보이지만, 결정 계수(Coefficient of Determination, R2)의 경우, 영산강의 적합도가 더 떨어지는 것을 알 수 있다. 전체적으로 유사량 추정 모델은 대부분의 수계에 대해 적절한 성능을 보였으나, 한강에서의 저유사량 범위에 대한 정확도 및 금강에서의 적합도 개선을 위한 추가적인 보정 작업이 추가된다면 더 높은 추정율이 제시될 것으로 예상된다.
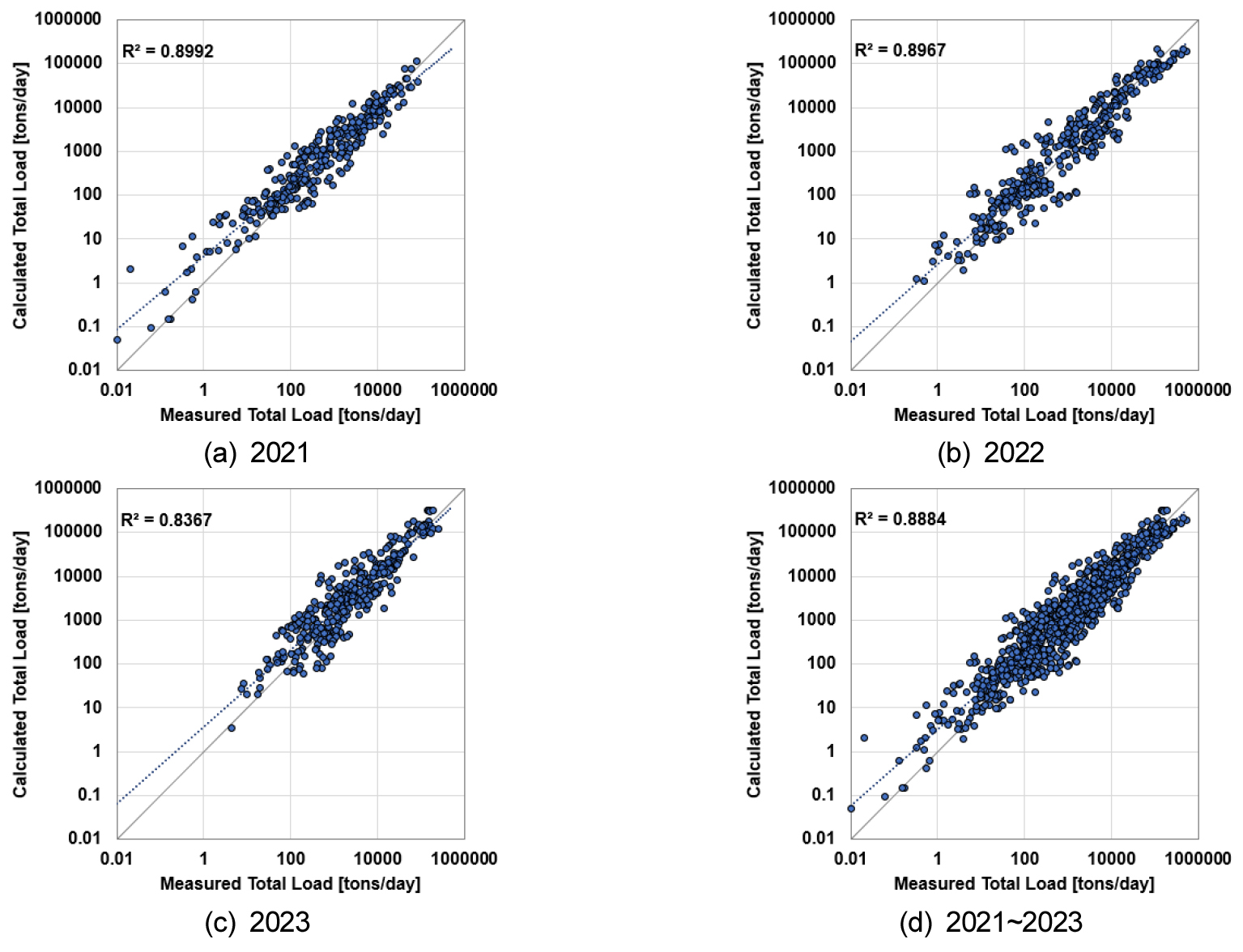
본 연구에서는 2021년부터 2023년까지 각각의 연도에 대한 유사량 추정 결과와 2021년부터 2023년의 모든 유사량 자료를 활용한 추정 결과를 비교하였다(Fig. 4). 각 연도에 대해 추정된 유사량은 측정값과의 일치도가 전반적으로 높았으며, 결정 계수 또한 평균 0.8 이상의 우수한 적합성을 보여주었다. 이를 통해 2021년부터 2023년 까지의 유사량 추정은 수리 조건 변동에 대해 상대적으로 높은 예측력을 보였음을 시사한다.
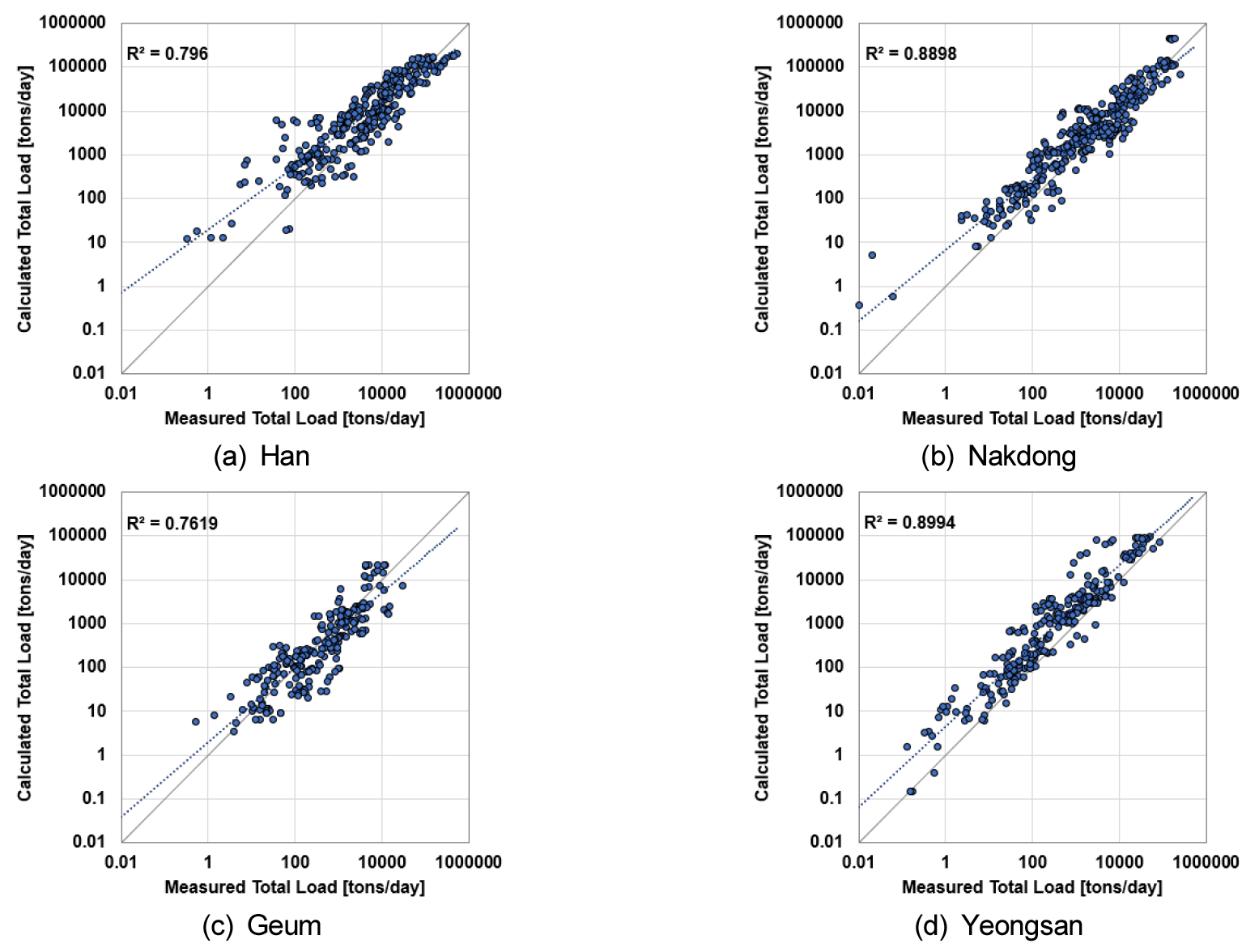
Fig. 3.
Comparison of the estimation of sediment discharge from 2021 to 2023 and the measured data using the existing model of Jang et al. (2023) by watershed.
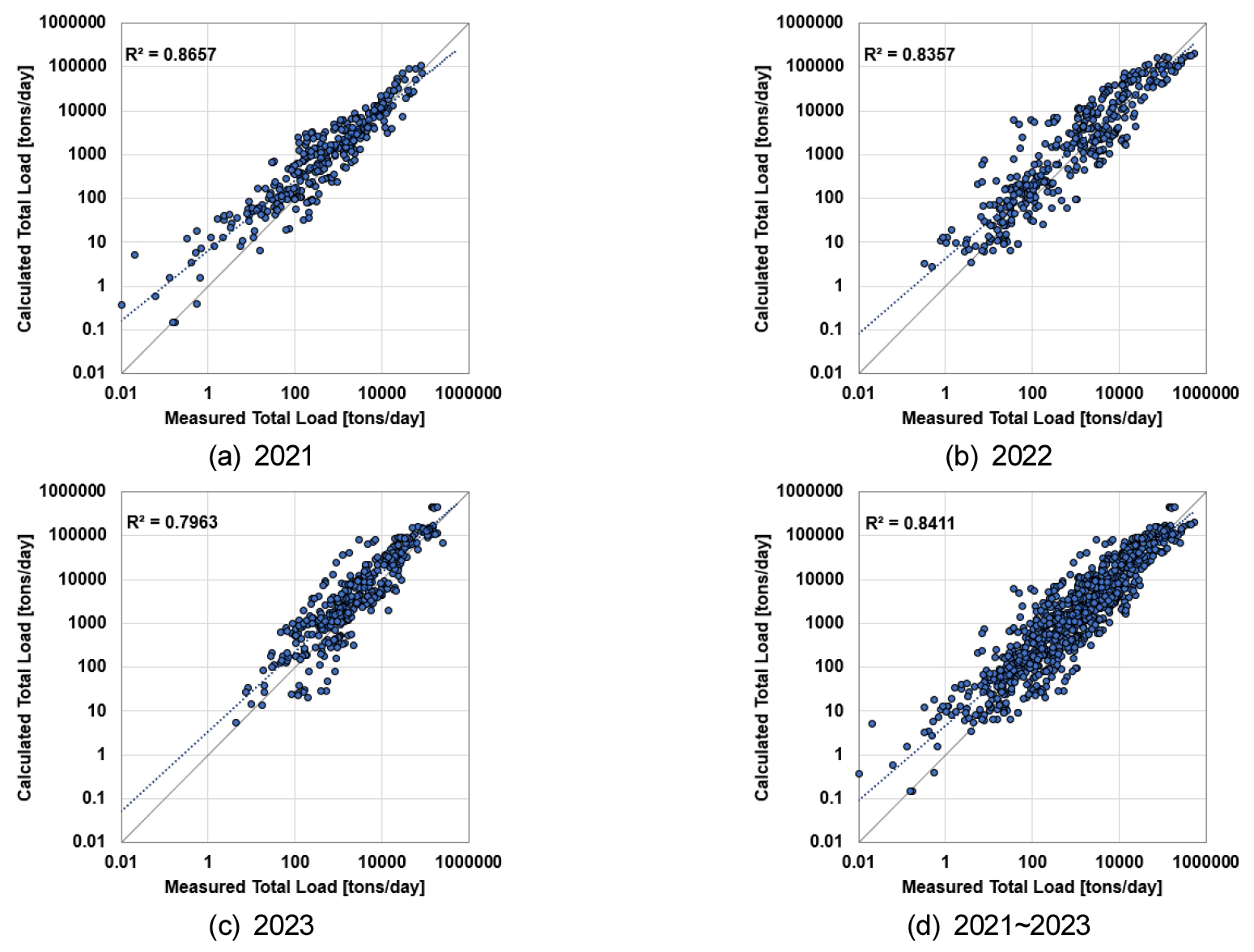
Fig. 4.
Comparison of the estimation of sediment discharge from 2021 to 2023 and the measured data using the existing model of Jang et al. (2023) by year.
3.2 추가 데이터를 활용한 Jang et al. (2023) 모델 개선
Jang et al. (2023) 모델은 높은 유사량 추정 정확도를 제시되고 있지만, 기존에 활용되었던 데이터에 최신의 데이터를 트레이닝에 추가한다면, 향상된 결과가 제시할 것으로 기대된다. 본 절에서는 기존 모델에서 활용된 2007년부터 2020년까지의 데이터와 함께 2021년부터 2023년까지 측정된 신규 데이터를 추가하여 트레이닝 후 개선된 모델을 통해 실측자료와 비교해보았다.
개선된 모델을 활용한 유역 별 유사량 추정 결과(Fig. 5), 전반적으로 결정 계수가 높아져 적합도가 향상되었음을 확인할 수 있다. 특히 영산강의 경우 결정계수 0.926의 높은 적합도를 보여주고 있다. 3.1절의 결과에서 보여주었던 한강 유역의 100 tons/day 이하의 저유사량에서의 오차가 상대적으로 크게 나타나는 현상도 다소 개선되었음을 알 수 있다.
연도별 분석 결과를 살펴보기 위해 연구에서는 2021년 연구에서는 2021년부터 2023년까지 관측된 가장 최신의 유사량 자료를 활용하여 2.2의 유사량 추정 모델을 평가하였다(Fig. 6). 수계 별 결과와 마찬가지로 결정 계수가 향상되었으며, 전 기간의 데이터를 기준으로 기존 0.8411에서 0.8884로 향상되었다. 이러한 분석 결과를 통해 예측도가 높은 추정 모델일지라도 지속적인 트레이닝 개선이 필요하다는 점을 입증할 수 있다.
3.3 유사량 추정 모델의 유사량 관계식 비교
다음 Eq. 3과 같은 유사량 관계식(Sediment Rating Curve, SRC)은 유량과 유사량의 추정을 위해 사용되는 가장 대표적인 관계식이다 (Campbell and Bauder 1940, Walling 1977, Walling and Webb 1981, Asselman 2000, Horowitz 2003). 추정된 유사량을 기반으로 유량과 유사량의 관계식을 도출하였다.
여기서, Qs 총 유사량(tons/day), Q는 유량(m3/s), a 및 b는 회귀분석을 통한 상수이다.
a는 특정 유량에서 초기 유사량 수준을 결정하는 계수로, 기본적으로 유량이 매우 작거나 1일 때 유사량의 값이 얼마나 되는지를 조정하는데 사용된다. 즉, 같은 유량 조건일 지라도 a가 더 클수록 유사량이 더 높게 산정된다. 따라서, 지역이나 강우-유출 특성에 따라 달라질 수 있는 기본 유사량의 수준을 의미한다. 지수 b의 경우, 유량 증가에 따라 유사량이 비례적으로 얼마나 증가하는지를 나타내며, 일반적으로 b가 클수록 유량에 대한 유사량의 민감도가 높아지는 것으로 알려져 있다. 예를 들어 b가 1보다 크면 유량이 증가할 때 유사량이 더욱 빠르게 증가하게 되며, b가 1보다 작으면 유사량이 상대적으로 완만하게 증가한다.
Fig. 1의 실측 유사량을 기반으로 한 유사량 관계식에서 a는 0.4251이며, b는 1.4658임을 확인하였다. Table 4의 2021년부터 2023년까지 모든 데이터를 활용한 유사량 관계식을 보면 a는 기존 Jang et al. (2023)의 모델이 0.923, 개선된 모델이 0.6911을 제시하였으며, b는 각각 1.4237과 1.4305를 제시하여 실측의 유사량 관계식과 매우 유사함을 알 수 있다. 연도별로는 2022년의 유사량이 유량 증가에 대해 가장 민감하게 반응할 것으로 제시되었다. 유역 별 결과를 살펴보면(Table 5), b에 비해 a 계수가 크게 변화하였음을 알 수 있다. 이러한 변화는 단순하게 새로운 데이터로 모델을 재훈련한 경우로 단정할 수도 있지만, 특정 유역에서 기본적인 유사량이 감소했음도 추론해 볼 수 있다. 즉, 유역 내 침식이나 퇴적 환경에 변화가 생겨 유역 내 식생 증가, 침식 방지 대책 또는 인프라 개선 등으로 인해 유사량이 줄어드는 방향으로 영향을 미쳤을 가능성 또한 배재할 수 없다. 이렇듯 도출되는 유사량 관계식의 정확도가 향상된다면, 하천 환경의 변화를 예측하기 위한 다양한 요인 중 하나로 활용할 수 있을 것이다.
Table 4.
The Comparison of sediment rating curve form existing and supplemented model by year
Table 5.
The Comparison of sediment rating curve form existing and supplemented model by watershed
4. 결 론
본 연구는 2021년부터 2023년까지의 최신 유사량 데이터를 활용하여 Jang et al. (2023) 모델의 예측 성능을 개선하고, 유사량 관계식을 통해 수계별, 연도별 특성을 구체적으로 분석하였다. 연구의 주요 결론은 다음과 같다:
첫째, Jang et al. (2023) 모델을 사용하여 2021년부터 2023년까지의 유사량을 추정하고, 이를 실측 자료와 비교한 결과, 대부분의 수계에서 모델은 우수한 성능을 보였다. 특히 낙동강에서는 높은 추정 정확도를 기록하였고, 한강에서는 저유사량 범위에서 오차가 상대적으로 크며, 금강은 적합도가 가장 낮게 산정되었다. 전체적으로 유사량 추정 모델은 높은 예측력을 보였으며, 결정 계수(R2)는 평균 0.8 이상으로 나타나 우수한 적합성을 확인할 수 있었다.
둘째, 2021년부터 2023년까지의 신규 데이터를 기존 2007년부터 2020년까지의 데이터와 함께 학습시켜 기존 모델을 개선한 결과, 개선된 모델은 예측 정확도가 향상되었으며, 결정 계수 또한 증가하였다. 특히 영산강에서는 가장 높은 결정 계수를 보였고, 한강 유역에서의 저유사량 예측 오차도 개선되었다. 연도별 분석 결과, 전체적으로 결정 계수가 향상되었으며, 이를 통해 예측 모델의 지속적인 트레이닝과 개선이 필요함을 확인할 수 있었다.
셋째, 기존 모델과 개선된 모델을 바탕으로 유사량 관계식을 도출하고, 이를 실측 유사량 관계식과 비교한 결과, 2021~2023년 데이터로 계산한 관계식이 실측 관계식과 매우 유사한 결과를 도출하였다. 특히 2022년의 유사량은 유량 증가에 민감하게 반응했으며, 유역별로 a 계수가 크게 변화한 것을 확인할 수 있었다. 이러한 변화를 통해 특정 유역에서 식생 증가, 침식 방지 대책 등 환경 변화가 유사량 감소에 영향을 미쳤을 가능성을 추측할 수 있으며, 이를 바탕으로 향상된 유사량 관계식이 하천 환경 변화를 예측하는 중요한 도구로 활용될 수 있음을 입증하였다.
본 연구는 최신 데이터의 지속적인 반영과 모델 개선이 예측 성능을 크게 향상시킬 수 있음을 실증적으로 보여주었으며, 유사량 관계식을 활용해 하천 환경 변화와 침식·퇴적 패턴을 보다 구체적으로 분석할 수 있는 가능성을 제시하였다. 향후 지속적인 유사량 관계 추정 모델 개발을 통해, 하천 관리, 환경 보호, 홍수 및 퇴적물 관리 등 다양한 응용 분야에서 중요한 역할을 할 것으로 기대된다.
