

1. 서 론
2. 데이터와 연구 지역
2.1 예보 자료: 동네예보 격자 데이터
2.2 실제 관측 자료: 시간당 강수량 관측 값
3. 연구 방법
3.1 CNN 모델 구조
3.2 모델 학습 설정 및 손실 함수
4. 결과 및 토의
4.1 예측시간별 예측 성능 비교
4.2 지점별 예측 성능 비교
4.3 극한 강수 이벤트 재현성 평가
4.4 통계적 보정(Quantile Mapping)과의 비교
5. 결 론
1. 서 론
최근 기후변화로 인한 집중호우, 국지성 폭우, 태풍 등 극한 강수 사상의 빈도가 전 세계적으로 증가하고 있다(IPCC 2022). 이러한 기상 재해는 인명 피해와 사회·경제적 손실을 초래하며, 도시 인프라, 수자원 관리, 재난 대응 시스템 전반에 심각한 영향을 미친다. 따라서 강수량의 시공간적 변화를 정밀하게 예측하는 것은 재해 예방 및 기후변화 적응 전략 수립에 있어 필수적인 과제가 되고 있다.
대한민국 기상청은 읍·면·동 단위의 동네예보 통해 지역별 상세한 기상정보를 제공하고 있으며, 이를 재난 대응과 국민생활 기상서비스의 자료로 활용하고 있다. 그러나 실제 예보 과정에서는 초기 조건의 불확실성, 복잡한 지형 효과 등으로 인해 강수 예측의 불확실 성과 체계적 오차가 발생하는 한계가 보고되고 있다(Sadeghi et al. 2021, Wang et al. 2023, Zhang et al. 2023). 또한, 기존의 통계적 보정 기법은 평균값 중심의 조정에는 비교적 유리하지만, 강수처럼 비선형성이 강하고 시·공간적으로 불균형한 분포를 가진 자료에 대해서는 빈도·극단치 조정에 한계를 보이는 것으로 보고되어 왔다(Tefera et al. 2023, Li et al. 2023, Cantalejo et al. 2024, Gneiting et al. 2025, Glahn et al. 1972, Scheuerer et al. 2015).
최근 딥러닝 기술, 특히 합성곱 신경망(Convolutional Neural Network, CNN) 기반의 모델들은 복잡하고 비선형적인 공간 패턴을 효과적으로 학습함으로써 강수 예측의 정확도를 향상시키는 것으로 보고되고 있다 (Badrinath et al. 2023, Ebtehaj et al. 2024, AL-Samrraie et al. 2025, Hess et al. 2005). Sadeghi et al. (2021)은 CNN 기반의 강수 예측 자료 후처리(post-processing) 기법이 위성 강수 자료의 평균제곱근오차(Root Mean Squared Error, RMSE)를 15–25% 감소시킬 수 있다고 보고하였다. 이처럼 딥러닝 기반 보정 기법은 기존 예보자료의 구조적 편향을 보완하고, 단기 강수예보의 정확도와 신뢰성을 향상시키는 데 활용될 수 있다. 때문에 본 연구에서는 기상청 동네예보 자료를 후처리 하여 보정하는 CNN 기반 다지점 단기강수예측 정보 보정 모델을 개발하였다. 제안 모델은 관측 자료와 동네예보의 예측 자료를 직접 입력에 포함하여 초기 예측시간에서의 예측성능을 강화하였다. 모델 학습에는 전국 78개 기상관측소 지점의 3년 6개월(2021.07~2024.12) 자료 중 2년 6개월(2021.07~2023.12)을 사용하였으며, 나머지 1년(2024.01~2024.12)의 데이터를 사용하여 성능을 평가하였다. 또한, 예측시간별 및 지점별 성능 분석을 수행하여 모델의 적용 가능성과 한계를 정량적으로 검증하였다. 본 연구의 결과는 기상청 동네예보의 예측 정확도를 향상시키고, 기후변화로 인한 극한 강수에 대한 대응 체계의 고도화에 기여할 수 있을 것으로 기대된다.
2. 데이터와 연구 지역
2.1 예보 자료: 동네예보 격자 데이터
본 연구에서 입력데이터로 사용되는 데이터 중 하나는 기상청에서 제공하는 동네예보의 단기예보 데이터이다. 동네예보는 지상 관측, 고층 관측, 위성 및 레이더 관측, 해상관측 데이터를 제공받아 3시간 간격으로 1일 8회의 예측을 수행하며, 약 5 km 해상도의 149×253 고정 격자로 Fig. 1과 같은 범위로 제공된다. 예측 결과는 3시간 간격으로 발표되며, 각 시점마다 1시간 간격으로 최대 55시간(예보 발표 시각에 따라 변동)까지 제공되고, 이 데이터들은 GIRB2 형식의 데이터로 사용자에게 제공된다. 연구에 사용된 CNN 모델의 입력으로 활용되는 데이터는 예보 발표 시각을 기준으로 +1 ~ 최대 +24시간 예측시간의 1시간 누적 강수 예보로 구성된다. Table 1은 동네예보의 발표 시각 및 예보 기간이며 Forecast Release Time은 UTC 기준이다.
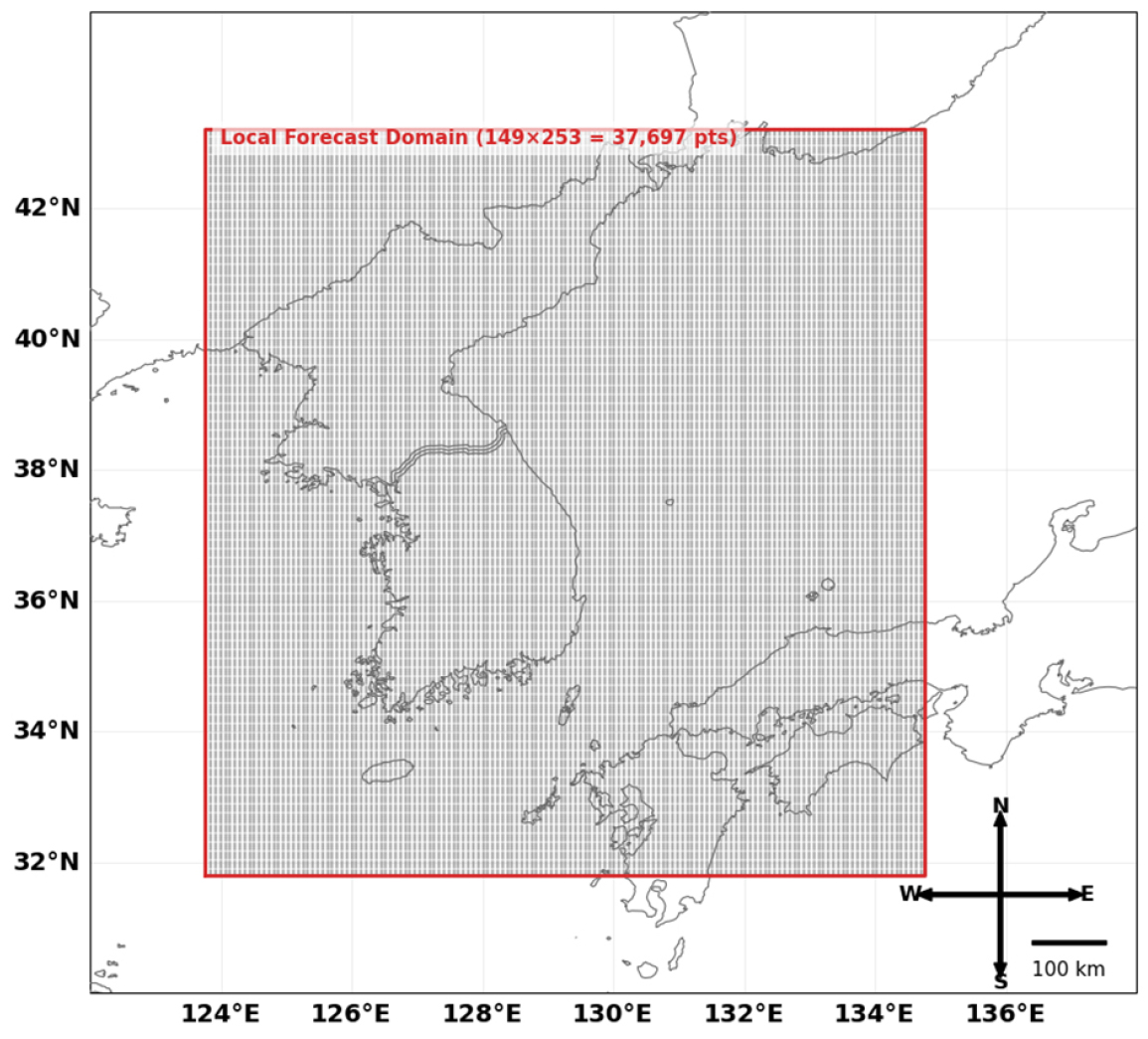
Table 1.
Announcement time and forecast period of the local forecast
2.2 실제 관측 자료: 시간당 강수량 관측 값
또 다른 입력 데이터로 사용되는 데이터는 기상청 종관기상관측망(Automated Synoptic Observing System, ASOS)에서 제공하는 78개 강수 관측소 데이터를 사용하였다. 관측소는 Fig. 2에서와 같이 전국에 고르게 분포 되어있고, 모든 관측소에서 1시간 단위의 강수량을 제공한다. 데이터는 훈련(2021.07-2023.06), 검증(2023. 07-2023.12), 평가(2024.01-2024.12)로 구분하여 사용하였다.
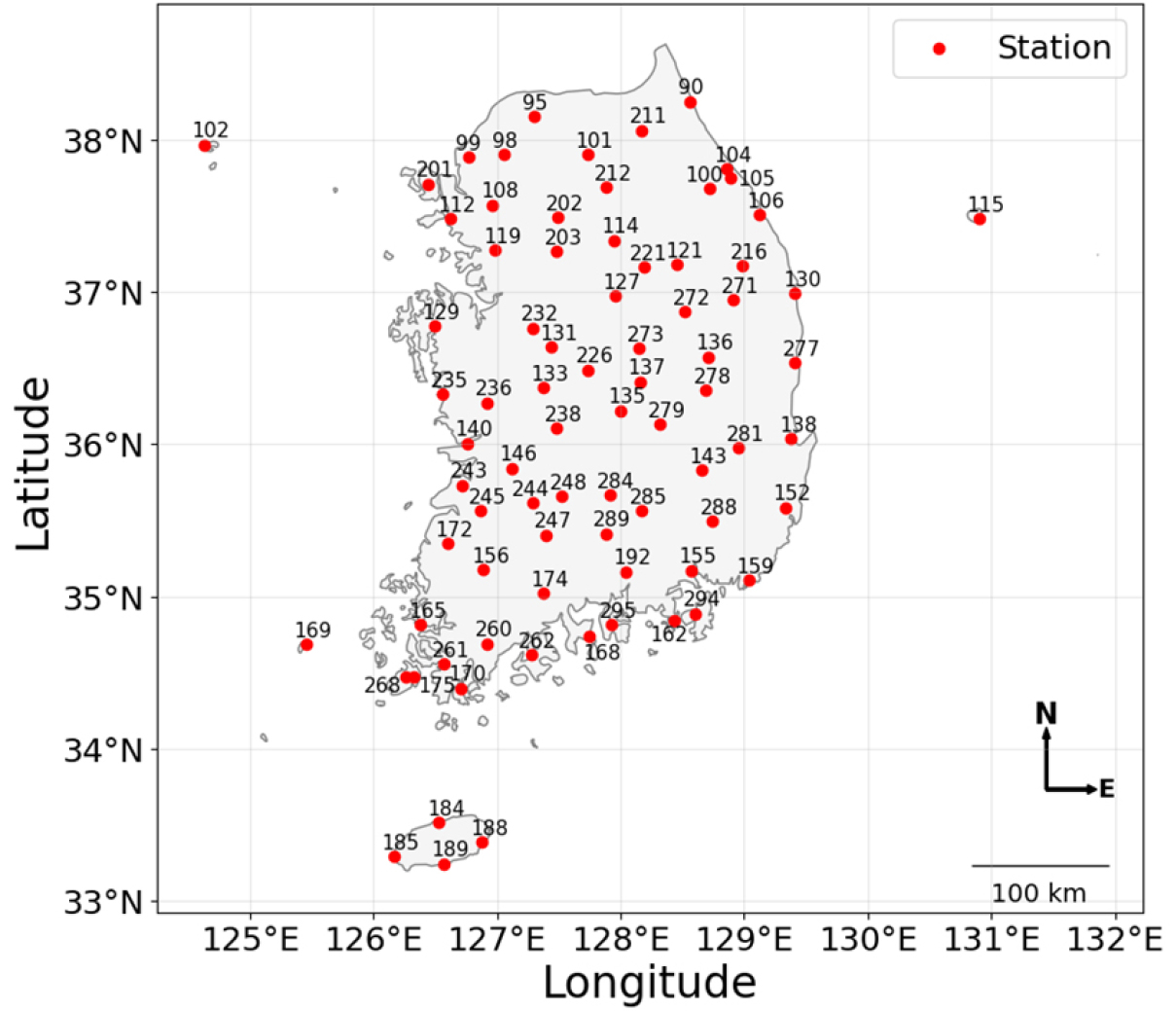
관측자료는 위경도 좌표를 기준으로 동네예보 격자 중 최근접 격자와 매칭하여 사용하였다. 모델은 다 지점 동시 보정 구조로 구현되며, 출력은 78개 지점의 강수량 벡터 형태이다.
3. 연구 방법
3.1 CNN 모델 구조
본 연구에서 제안하는 모델은 Fig. 3과 같은 구조의 여러 관측소 지점의 강수량을 동시에 산출하는 다지점 보정 구조의 CNN 모델로, 입력 데이터의 공간 패턴을 학습한 후 복수 관측소의 강수량을 동시에 출력하도록 설계하였다. 모델은 PyTorch를 기반으로 구현하였으며, 주요 구조는 합성곱 층(Convolutional layers, Conv layer), 풀링 층(Pooling layer, Pool layer), 완전 연결 계층(Fully Connected layers, FC layer)으로 구성하였다. 입력 데이터는 앞서 설명한 원 예보 격자로, 입력 채널 수는 예측 시점 T에 따라 T+1에서 T+10까지 최대 10개의 파일과 마스킹 채널 1개로 결정된다. 입력 채널을 최대 T+10까지 사용한 이유는 학습 장비가 수용할 수 있는 메모리 및 채널 수의 한계에 기초한 결정으로, 자원 제약을 고려한 실용적 선택이다. 또한 T+10을 초과하는 채널을 추가하는 경우 계산 비용은 급격히 증가하는 반면 성능 향상은 제한적일 것으로 예상되어, 효율성과 효과성을 균형 있게 고려하여 T+10으로 제한하였다.
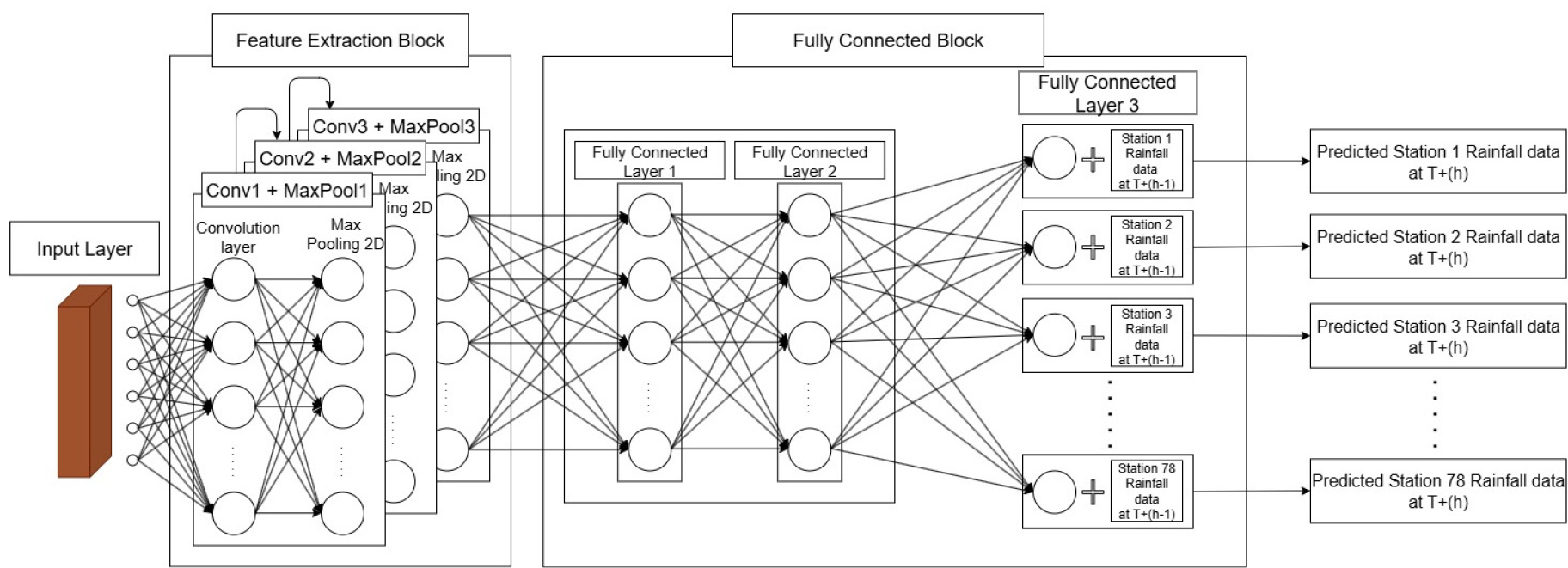
모델의 각각의 층은 다음과 같이 정의된다. 첫 번째 합성곱 층(Conv layer 1)은 입력 채널을 8개의 특징 맵으로 변환하며, 커널 크기 5×5, 패딩 2를 적용하였다. 또한 첫번째 풀링 층(Pool layer 1, 2×2)이 특징 맵의 해상도를 줄인다. 두 번째 합성곱 층(Conv layer 2)은 8개의 입력을 커널 3×3, 패딩1의 16개의 특징 맵으로 변환한 후 마찬가지로 풀링 층(Pool layer 2, 2×2)을 적용하였다. 세 번째 합성곱 층(Conv layer 3)은 16개를 32개로 변환(커널 3×3, 패딩1)하고, 이 또한 풀링 층(Pool layer 3, 2×2)을 적용하였다. 또한 합성곱 층과 풀링 사이마다 ReLU (Rectified Linear Unit) 활성화 함수가 적용되었다. 이러한 합성곱-활성화 함수-풀링 과정은 공간적 특징을 계층적으로 추출하며, 최종 합성곱 출력은 평탄화 후 1차원 벡터로 변환되고, 그 크기는 입력 예시를 통해 미리 계산된다.
평탄화된 특징 벡터는 FC layer로 전달된다. 첫 번째 FC layer의 차원을 128차원으로 압축하고, 두 번째에는 128차원을 64차원으로 압축시킨다. 각 층에는 ReLU가 적용된다.
이 후 모델의 핵심인 다 지점 출력 구조로 이어지는데, 64차원으로 압축된 특징 벡터에 각 관측소의 이전 시점 강수량 (예측 시점 T=1 시 현재의 실제 강수량, T>1 시 이전 시간의 예측 값)을 연결(concatenate)하여 65차원 입력을 만든다. 이를 78개의 개별 선형 계층으로 처리하여 각 관측소별 강수량을 동시에 산출한다. 해당 구조는 합성곱 계층을 통해 원 예보 격자의 공간 패턴(강수 분포, 이동 등)을 학습하고, 지점별 연결을 통해 지역 특성을 반영한다.
3.2 모델 학습 설정 및 손실 함수
학습은 Ubuntu 기반의 리눅스 서버 환경에서 수행되었다. 해당 서버는 Intel Xeon Silver 4310 프로세서 (2.10 GHz, 12코어 × 2소켓, 총 48스레드)를 탑제하고 있으며, 251 GB의 메인 메모리(RAM)를 보유하고 있다. 연산 가속기로는 NVIDIA RTX A6000 GPU가 2개 장착되어 있으며, 각 GPU는 49.1 GB의 전용 메모리를 제공한다. CUDA 버전은 12.4DLAU, NVIDIA 드라이버 버전은 550.163.01이다. 데이터 로더는 TensorDataset과 DataLoader를 사용하여 구성하였고, 배치 크기를 32로 설정하여 메모리와 학습 속도의 균형을 맞췄다. 최적화 알고리즘으로는 Adaptive Moment Estimation (ADAM)을 사용하였고, 학습률(learning rate)은 0.001로 설정하였다. 학습은 총 100 epoch 동안 진행되었으며, 각 epoch 후 검증 손실함수(validation loss)를 계산하여 최저 손실 모델을 저장함으로써 과적합을 방지하고 최적 성능을 확보했다. 합성곱 계층 수, 커널 크기, 배치 크기, 학습률, Epoch 수, Hybrid Loss의 가중치 등 주요 하이퍼파라미터는 검증 데이터셋을 활용한 경험적 탐색 과정을 통해 선정하였다. 즉, 다양한 조합을 반복적으로 실험하여 안정적이고 일관된 성능을 보이는 구성을 최종 채택하였다. 이는 단기예보 보정 문제에서 실용성과 경량화를 우선한 결과이며, 향후에는 보다 체계적인 민감도 분석을 수행할 예정이다.
학습 과정에서 강수일과 무강수 일의 불균형 문제를 해소하기 위해 학습 데이터셋에서 강수일과 무강수 일을 1:1 비율로 언더샘플링(under sampling) 하였다. Buda et al. (2018)에 따르면, CNN에서 데이터 불균형 문제를 해결하기 위해 샘플링 기법을 사용하는 것이 소수 데이터를 강조하여 모델 편향을 줄이고 성능을 향상시키는데 효과적이고, 이는 강수 데이터처럼 편향된 분포에서 과적합 없이 학습을 안정화하는데 도움이 된다고 한다. 이러한 접근을 통해 모델이 무강수 사례에 치우치지 않고 강수 이벤트를 효과적으로 학습하도록 하였다.
오버샘플링(over sampling)도 고려하였지만, 강수 이벤트를 과도하게 증폭시켜 실제보다 강수가 많이 발생하는 것처럼 학습할 위험이 있었다. 실제 우리나라 기후 특성상 무강수일이 더 많기 때문에, 오버샘플링은 오히려 예측의 편향을 키울 수 있다. 따라서 본 연구는 무강수와 강수 사례를 균형 있게 학습하기 위해 언더샘플링을 채택하였다. 한편, class weighting은 손실함수에서 강수 이벤트에 더 큰 가중치를 부여하는 방법이지만, 본 연구에서는 구현 단순성과 손실 스케일 안정성을 고려해 채택하지 않았다.
손실 함수로는 HybridLoss를 사용하였다. 사용된 HybridLoss는 평균 제곱 오차(Mean Squared Error, MSE)와 평균 절대 오차(Mean Absolute Error, MAE)를 조합한 형태로, 의 수식으로 구성 되어있다. MAE를 추가한 이유는 큰 오차에 대한 민감도를 줄여 모델의 안정성을 늘리기 위함으로, Willmott and Matsuura (2005)에 따르면 MAE는 MSE보다 큰 오차를 과도하게 강조하지 않아 모델의 평균 성능을 안정적으로 평가할 수 있고, 이는 강수 예측처럼 이상치가 빈번한 데이터에서 견고한 학습을 유도한다고 한다. 또한, 강수량의 비음수(non-negative) 물리 제약을 반영하기 위해 일방향 음수 패널티를 추가하였다. 이는 입력 단계에서 바다 영역을 -1로 마스킹하는 과정에서 학습 초기에 모델이 음수 출력을 모사하려는 경향을 손실 항으로 제지하여, 물리적으로 불가능한 예측(강수량 0)을 억제하기 위함이다. 구체적으로, 배치 크기를 B, 지점 수를 S, 예측값과 관측값을 , 라 할 때 최종 손실 함수는 다음과 같이 정의된다.
여기서 마지막 항은 일 때만 기여하는 선형 패널티로, mean[ReLU(] 형태에 가중치 𝜆를 곱해 더한다. 이러한 제약은 모델의 학습 안전성을 높이고, 신뢰성을 높이는데. Rosca et al. (2023)은 회귀 손실에 물리 제약을 반영한 패널티를 추가하면 모델 안정성 및 물리적 타당성을 동시에 개선할 수 있다고 보고한 바 있다. 본연구에서는 𝜆를 조정하여 음수 예측 비율을 낮추면서도 MSE와 MAE 값이 최소화되도록 선정하였다. 이와 같은 설정으로 모델의 안정성을 높이고, 강수 데이터의 편향성을 고려하여 이를 보안하는 견고한 학습을 유도한다.
4. 결과 및 토의
본 절에서는 제안된 CNN기반 다지점 단기강수예측 정보 보정 모델의 성능을 평가 데이터셋(2024.01~ 2024.12)을 기반으로 평가한 결과를 제시한다. 평가 지표로는 평균 제곱근 오차(Root Mean Squared Error, RMSE)와 상관계수(Correlation Coefficient, Corr)을 사용하였으며, 각 예측시간(T=1~24)별로 10회 반복 학습 후 평균하였다.
4.1 예측시간별 예측 성능 비교
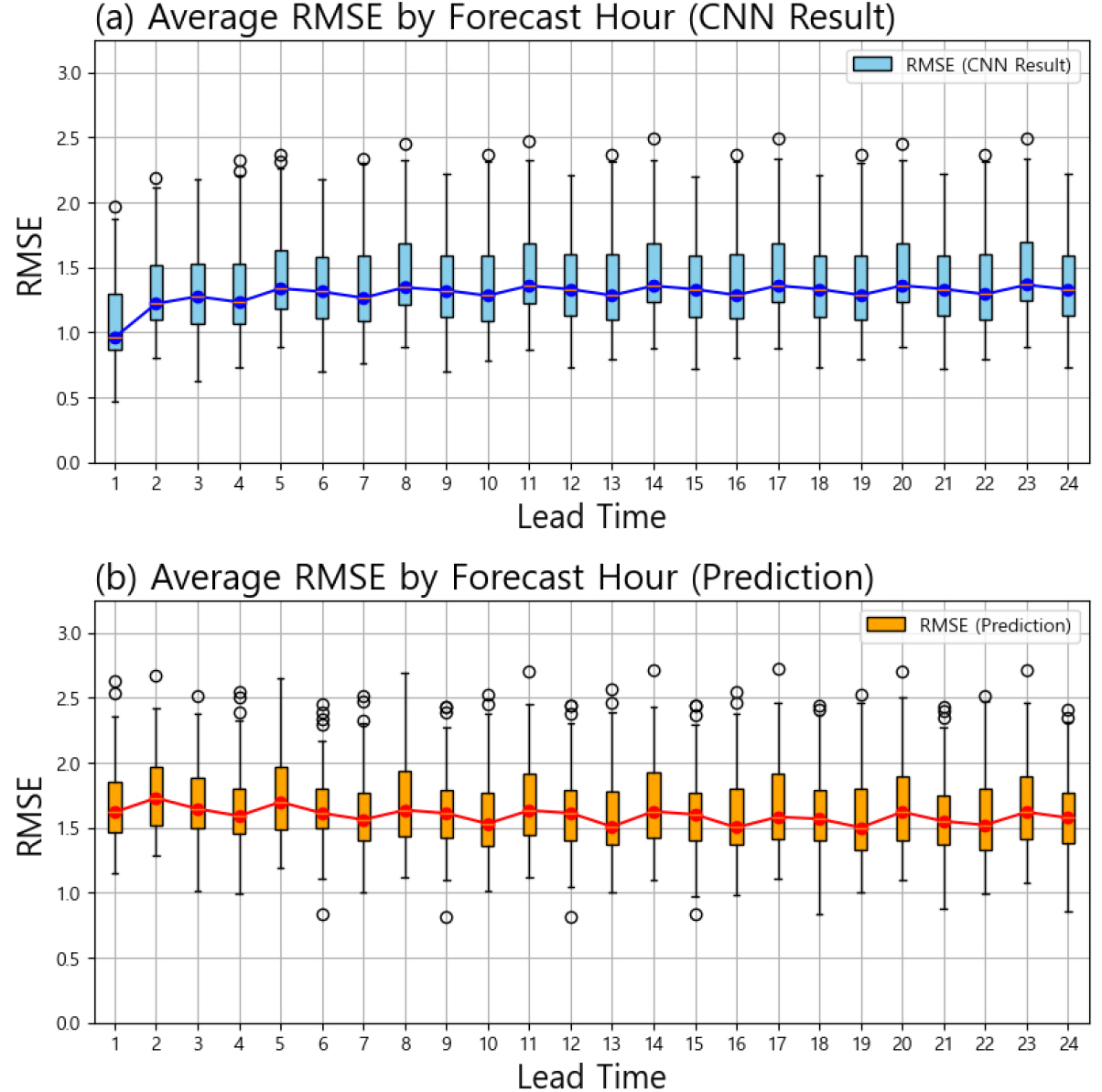
Fig. 4는 T=1~24에 대한 예측시간별 RMSE의 평균 변화를, Fig. 5는 동일 구간의 Corr 평균 변화를 나타낸다. CNN기반 다지점 단기강수예측 정보 보정 모델은 1~24시간 예측시간 전 구간에서 원 예보 대비 RMSE를 평균 16.50% 감소시키고, Corr을 평균 53.90% 향상시켰다. 특히 세번째 FC layer에서 현시점의 실제 강수량을 입력으로 사용한 T=1에서는 RMSE가 37.16% 감소하고 Corr이 174.42% 증가하여 예측 성능이 크게 개선되었음을 확인할 수 있다. T<7인 구간에서 개선폭이 특히 컸으며, 이 구간에서의 RMSE 평균 감소율은 17.75~37.16%, Corr 평균 증가율은 61.58~174.42%를 기록하였다.
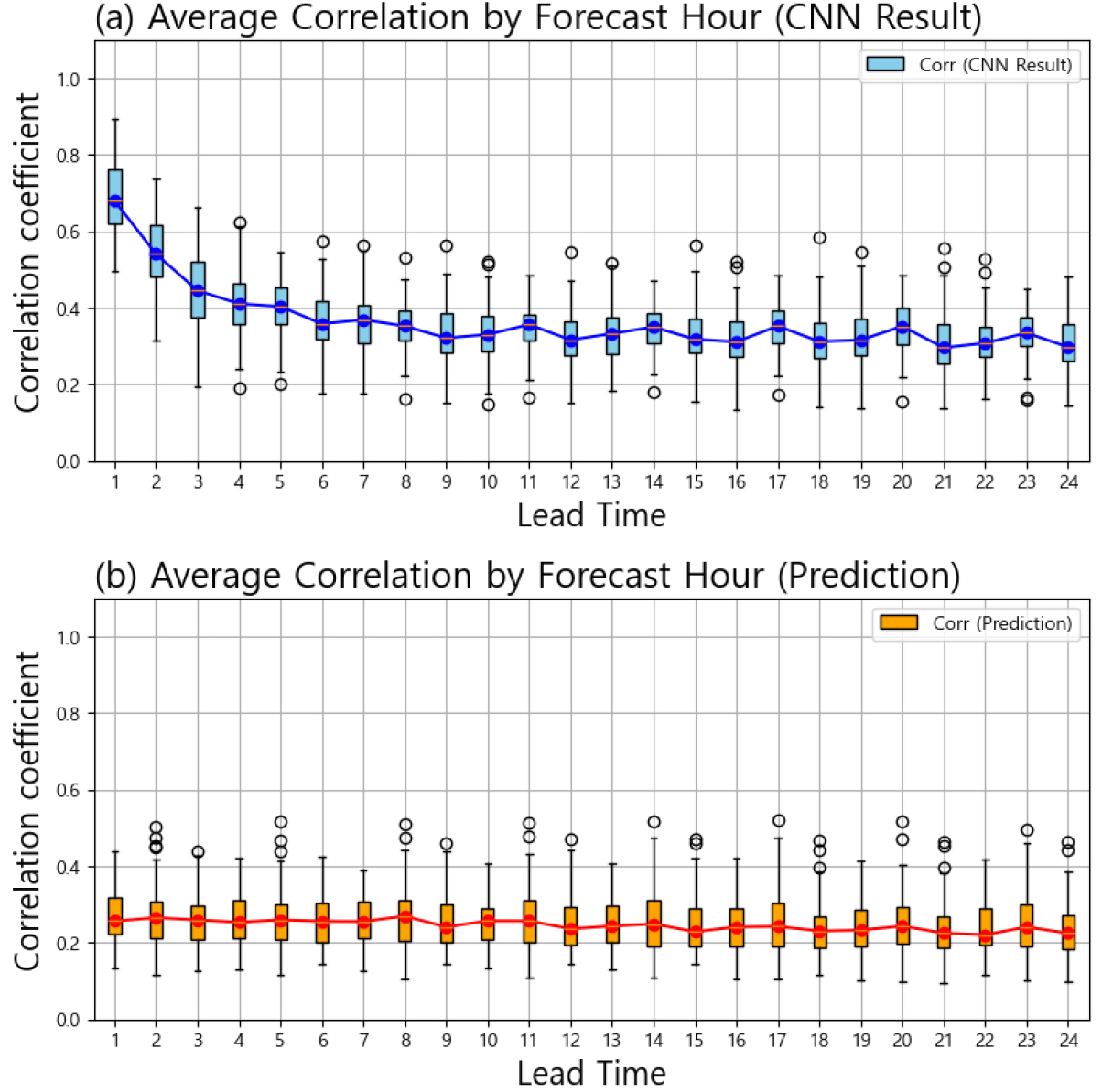
이러한 성능 향상은 CNN의 합성곱 계층이 입력 데이터의 공간적 패턴을 효과적으로 학습하여 원 예보의 구조적 오차를 보정한 결과로 해석된다. Sadeghi et al. (2021)은 CNN 기반 후처리 기법이 강수 예측 RMSE를 15~25% 줄일 수 있다고 보고하였으며, 본 연구의 평균 16.5% 감소와 유사한 수준이다. 특히 T=1에서의 두드러진 개선은 세번째 FC layer에서 관측 데이터를 직접 활용함으로써 초기 예측 단계의 신뢰도를 크게 높였기 때문으로, 이는 Lim et al. (2021)이 이전 시점 자료를 추가 입력하여 시계열 예측 성능을 개선한 CNN 모델과 유사한 접근이다. 또한, 강수 데이터의 비대칭 분포(skewed distribution)를 고려한 1:1 비율의 샘플링 기법이 모델의 일반화 성능을 높이는 데 기여했으며, 이는 Buda et al. (2018)이 언더 샘플링과 오버 샘플링을 통해 클래스 불균형 문제를 완화한 연구와 유사한 결과를 보인다. 더불어, MAE와 MSE를 결합한 Hybrid Loss를 사용하고, 음수 penalty 항을 추가하여 음수 예측을 억제한 것이 안정성 확보에 긍정적인 영향을 미쳤다(Willmott and Matsuura, 2005).
CNN기반 다지점 단기강수예측 정보 보정 모델의 예측 정확도는 예측시간 증가에 따라 점차 감소하는 경향을 보였다. Fig. 4(a)와 Fig. 5(a)에서 확인할 수 있듯이, RMSE는 T=2 시점에서 1.07에서 1.33으로 증가한 후, T=2~4 구간에서 1.31~1.34 범위로 비교적 안정적으로 유지되었다. 이는 과거 데이터(T=1~4)의 높은 자기 상관성(autocorrelation) 덕분에 단기 예측의 안정성이 유지된 것으로, Wang and Tian (2021)의 자기회귀 모델 분석에서 단기 예측 구간의 오차가 최소화되는 패턴과 일치한다. 그러나 T=5 시점에서 1.44로 상승한 이후, T=5~24 구간에서 RMSE는 1.30~1.49 범위 내에서 증가와 감소를 반복하였다.
Corr 값 또한 T=1에서 0.69로 시작하여 T=1~7 구간에서 0.36까지 지속적으로 감소한 뒤, T=8~24 구간에서는 0.31~0.35 범위에서 진폭을 유지하며 변동하였다. 이러한 패턴은 중장기 예측시간에서 모델의 보정 능력이 제한되고, 원 예보 자료의 진폭을 따라가는 경향을 보인 결과로 해석된다. 이러한 예측시간별 RMSE와 Corr에서 나타나는 주기적 변동은(1) 국지 순환과 대류 활성 시각이 만드는 일변화, (2) 자료동화 및 초기화 후 예보계가 안정화되는 spin-up/동화 주기, (3) CNN기반 단기강수예측 정보 보정모형이 진폭 편향은 줄이되 위상(발생 시각, 이동속도)오차는 일부 잔존시키는 특성이 복합적으로 작용한 결과로 해석된다. 특히 초기 3~6시간 구간에서 성능이 안정적인 것은 예보의 초기 적분 안정화 과정과 관측자료 활용 효과 가 반영된 것으로 보인다. 종합적으로, 본 연구의 CNN 모델은 T <7인 예측시간에서 매우 높은 보정 성능을 보였으나, 예측시간 증가에 따라 오차 누적 및 원 예보 자료의 한계로 인해 성능이 점차 저하되는 특징을 나타냈다.
4.2 지점별 예측 성능 비교
Fig. 6은 전체 리드타임의 지점별 평균 RMSE와 Corr그래프로, 지점별 성능을 분석한 결과 대부분의 관측 지점에서 CNN 기반 다지점 단기강수예측 정보 보정 모델이 원 예보 대비 안정적인 보정 효과를 보여주었지만, 일부 지점의 특정 예측시간에서는 RMSE가 증가(원 예보 대비 최대 6.55% 증가)하거나 Corr이 감소(원 예보 대비 최대 40.91% 증가)하는 사례도 관찰되었다. Fig. 7은 T=12 예측시간에서 CNN 기반 다지점 단기강수예측 정보 보정 모델의 결과값과 원 예보값의 RMSE 및 Corr을 비교한 그래프로, 개선 지점의 비율은 RMSE 기준 95.83%, Corr 기준 84.72%였으나, 각각 RMSE는 3개 지점(4.17%), Corr은 11개 지점(15.28%)에서 악화가 나타났다.
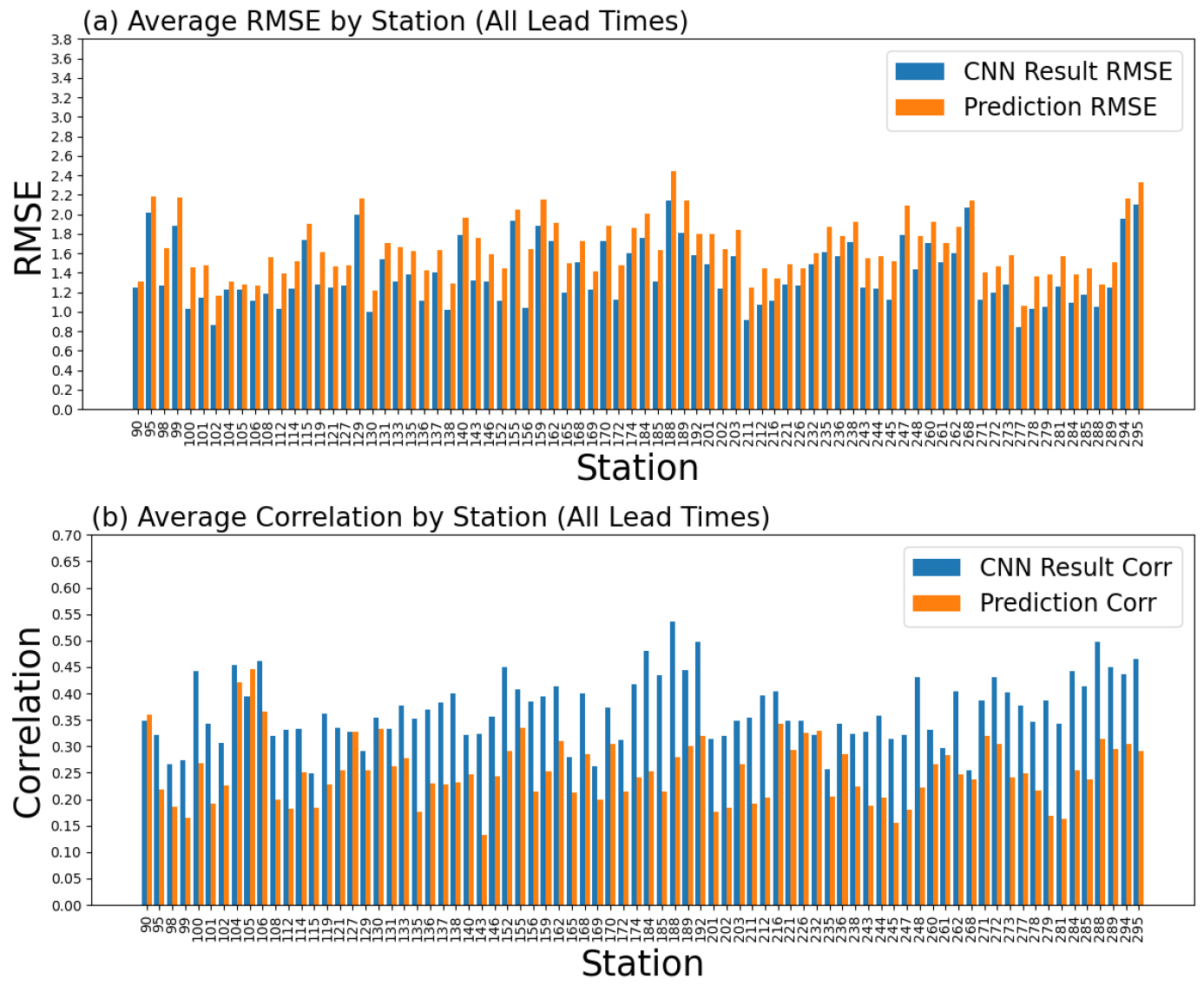
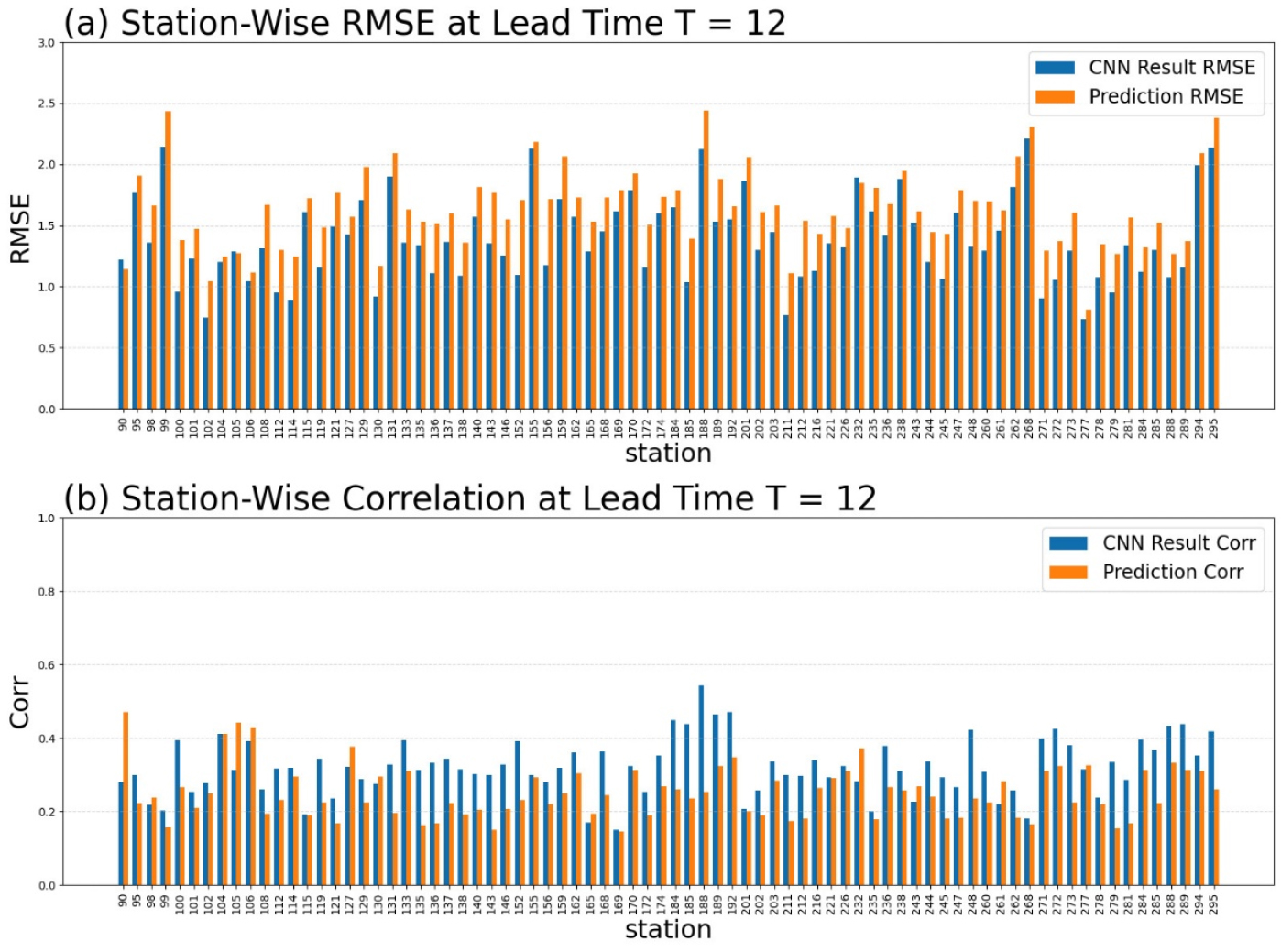
개선 효과가 뛰어난 3개 지점(제주 184, 성산 188, 진주 192)과 개선 효과가 낮은 3개 지점(속초 90, 강릉 105, 천안 232)을 선별하여 예측시간별 RMSE 및 Corr 변화를 심층 분석하였다(Fig. 8, Fig. 9). 개선 지점들은 대부분 예측시간에서 RMSE 감소 및 Corr 증가가 꾸준히 나타났고, 특히 T≤5에서 개선 폭이 컸다. 반면, 하위 지점들은 T 에서는 성능 개선이 있었지만, T>5에서부터 성능이 떨어지는 경향을 보였다. 이러한 차이는 지형과 강수 이동 경로의 영향과 관련될 가능성이 있다. 개선 정도가 컸던 지점(제주, 성산, 진주)은 해안에 인접해 해상에서 유입된 강수대가 큰 변형 없이 상륙하는 경우가 상대적으로 많아 강수 패턴 보존이 용이 했을 수 있다. 반면 성능 개선이 적었던 지점의 경우 천안은 내륙에 위치하여 강수가 서에서 동으로 이동하는 동안 강수 소진이 발생 해 도달 시점의 패턴 대비가 약화될 수 있고, 속초 강릉은 동해안에 위치하되 대부분의 강수가 서에서 동으로 이동하는 경우가 많은 대한민국의 특성상, 비구름이 산맥을 횡단하는 과정에서 지형성 강수 효과가 겹치며 패턴 유지가 어려웠을 가능성이 있다.
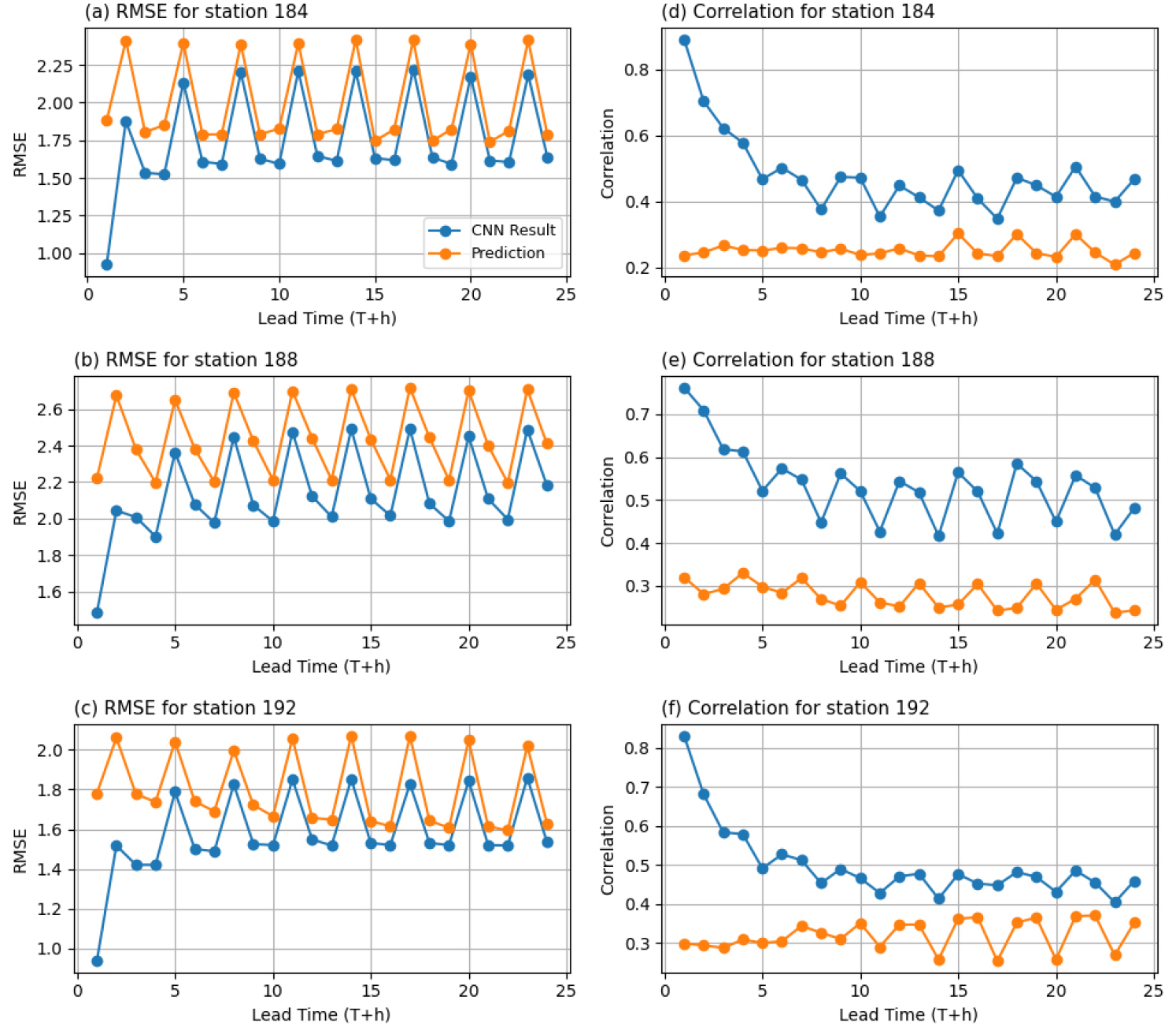
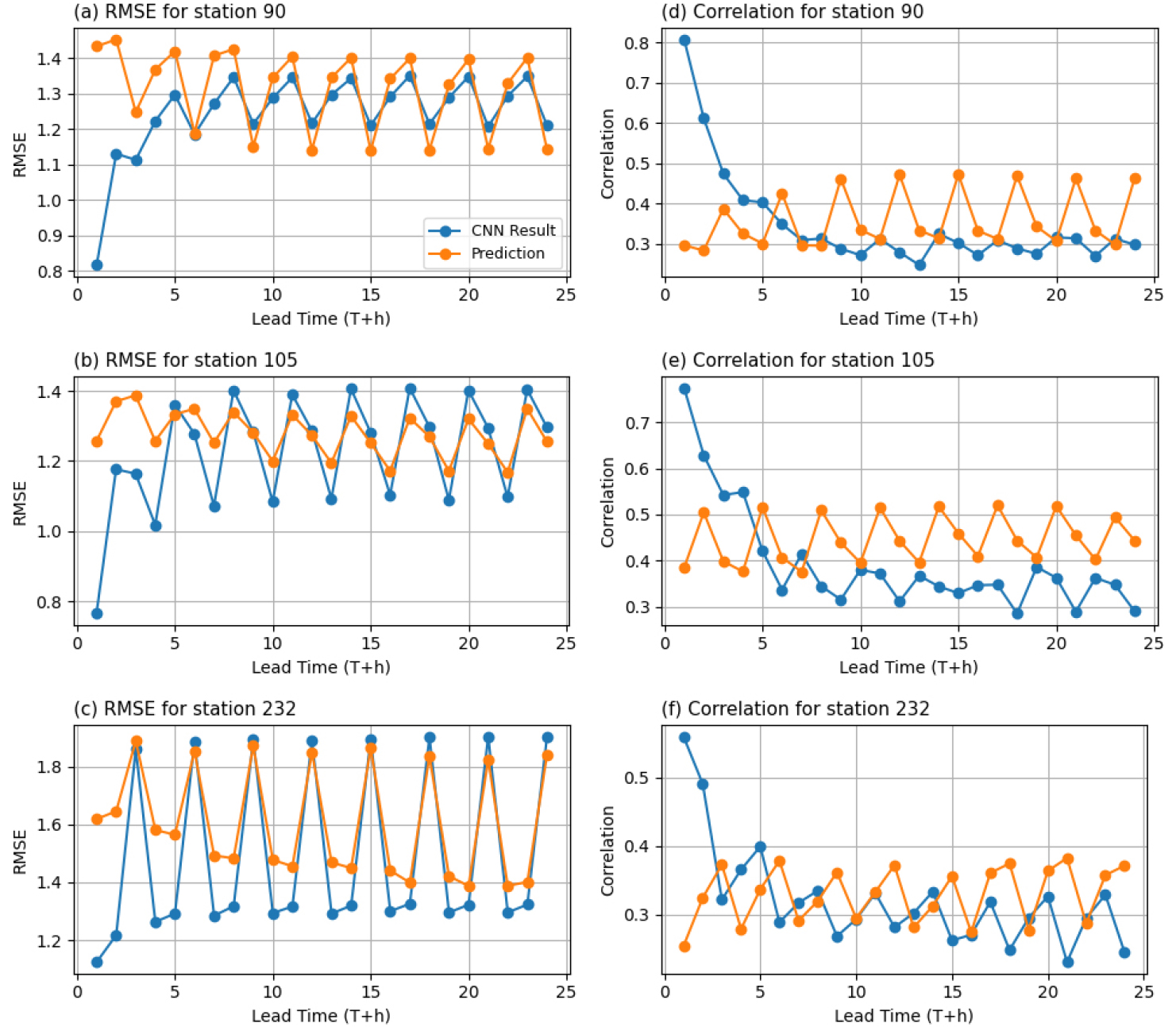
이러한 결과는 CNN 기반 보정 성능이 단순히 지리적 위치보다는, 입력 데이터의 공간 상관성, 강수 패턴의 변동성, 관측 자료의 품질 등 복합적 요인에 의해 결정된다는 것을 보여준다. 특히 공간적 이질성을 고려하지 않으면 일부 지점에서 성능 편차가 발생할 수 있다. Li et al. (2022) 에 따르면, CNN 기반 후처리 모델이 공간 정보와 대기 순환 변수를 함께 활용할 경우 예측 정확도, 판별력, 신뢰도 등을 최대 약 10 % 향상시킬 수 있음을 확인하였다. 또한, Vaughan et al. (2021)에 따르면, convCNP (Convolutional Conditional Neural Processes)와 같은 다 지점 통계적 다운 스케일링 모델을 통해 접근 시, 극한 강수 이벤트 표현 성능을 포함한 지역 보정 성능이 기존 방법을 뛰어넘을 수 있음을 보였으며, 이는 본 연구의 지점별 성능 차이 분석을 강화할 수 있는 이론적 근거가 된다.
본 연구에서 개발한 CNN 기반 강수량 보정 모형은 T≤5 에서 원 예보 대비 현저히 우수한 성능을 보였으며, 특히 T=1에서 관측 강수량을 직접 입력하는 구조를 통해 초기 예측의 신뢰도를 크게 향상시킨 것이 가장 큰 강점이다. 이는 예측 초기 단계에서의 정확도 개선이 후속 예측시간으로 전파되어 단기 예측 전반의 성능을 안정적으로 유지하게 만드는 핵심 메커니즘으로 작용하였다. 또한, 강수 데이터의 불균형 문제를 완화하는 샘플링 기법과 MAE·MSE 결합의 Hybrid Loss 설계, 그리고 음수 예측 억제 기법을 통합함으로써 모델의 일반화 능력과 안정성을 동시에 확보하였다. 지점별 분석 결과, 대부분의 지역에서 초기 예측시간에 일관된 개선 효과를 보였으며, 공간 상관성과 자료 품질이 확보된 경우 중·장기 예측시간에서도 성능이 유지될 수 있음을 확인하였다. 이러한 결과는 단순한 통계적 보정 기법을 넘어, 시공간적 패턴을 학습하여 다양한 지역과 기상 조건에서 적용 가능한 강수 예측 보정 프레임워크를 제시하였다는 점에서 학문적·실용적 의의가 있다.
4.3 극한 강수 이벤트 재현성 평가
기상청의 극한 강수 정의(1시간 누적 강수량이 50 mm 이상이면서 3시간 누적강수량이 90 mm 이상인 경우, 혹은 1시간 누적 강수량이 72 mm 이상인 경우)를 적용하여 테스트 구간에서 총 160건의 극한 강수 이벤트를 추출한 후 CNN 기반 다지점 단기강수예측 정보 보정 모델과 원 예보의 MAE를 비교한 Fig. 10 그래프를 생성하였다.
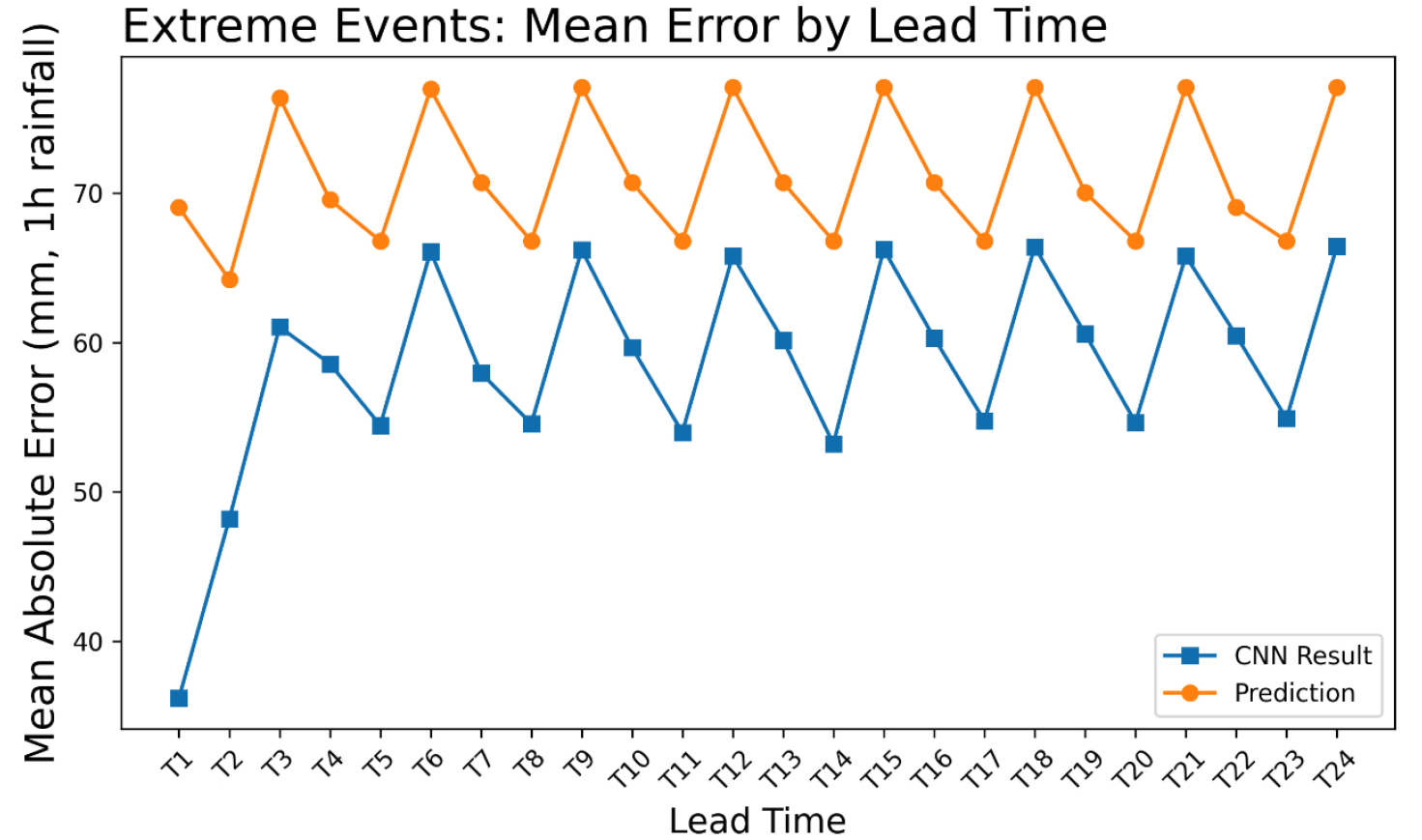
이들 극한 이벤트에 대해 원 예보와 CNN 기반 다지점 단기강수예측 정보 보정 모델의 결과를 비교한 결과, CNN 기반 다지점 단기강수예측 정보 보정 모델은 극한값을 완벽히 포착하지는 못하였으나 원 예보보다 관측치에 더 근접한 강수량을 산출하였다. 전체 160건 중 CNN 기반 다지점 단기강수예측 정보 보정 모델이 더 관측값에 가까웠던 사례가 140건(87.5%), 원 예보가 우세했던 사례는 20건(12.5%)로 압도적으로 많았다. 또한 평균 오차 역시 원 예보가 71.2 mm였던 반면 CNN 기반 다지점 단기강수예측 정보 보정 모델은 58.6 mm로 소폭 감소하였다.
특히 T≤5에서 개선 효과가 뚜렷하게 나타났다. T≤5에서 원 예보는 극한 이벤트 시 평균 69.1 mm의 오차를 보인 반면, CNN 기반 다지점 단기강수예측 정보 보정 모델은 43.6 mm로 크게 줄어들어, 강수 강도의 크기를 보다 현실적으로 추정하였다. 이는 CNN 기반 다지점 단기강수예측 정보 보정 모델이 극한 강수의 절대적인 크기를 완전히 재현하기는 어렵더라도, 원 예보 대비 경향성을 충실히 반영하여 극한 사건 발생 가능성을 보다 명확이 드러낸다고 볼 수 있다. 예측시간이 길어질수록 원 예보와 CNN 기반 다지점 단기강수예측 정보 보정 모델 모두 오차가 증가하고 CNN 기반 다지점 단기강수예측 정보 보정 모델의 우위가 줄어드는 경향을 보였지만, 전체적으로 CNN 기반 다지점 단기강수예측 정보 보정 모델이 원 예보보다 안정적인 성능을 유지하였다. 이러한결과는 CNN 기반 다지점 단기강수예측 정보 보정 모델이 일반적인 강수뿐만 아니라 극한 기상 조건에서도 일정 수준의 성능 개선을 제공할 수 있음을 보여준다.
4.4 통계적 보정(Quantile Mapping)과의 비교
본 절에서는 제안한 CNN 기반 다지점 단기강수예측 정보 보정 모델을 전통적 통계 보정인 Quantile Mapping (QM)과 비교하였다. QM은 예보값의 누적분포함수(Cumulative Distribution Function, CDF)를 관측 분포에 정합시켜 분위수 단위로 값을 매핑하는 방식으로, 수치예보의 구조적 편향을 줄이는 데 널리 사용되어 왔다. 본 연구 학습 구간(과거 2년)에서 예보–관측 분위수 매핑을 학습하고, 검증(6개월) 과정을 거친 뒤, 최근 1년에 한정해 원 예보에 QM 보정을 적용하여 CNN 기반 다지점 단기강수예측 정보 보정 모델의 결과값과 QM 보정을 적용한 결과값을 공정하게 비교하였다.
그 결과, Fig. 11에서 볼 수 있듯 대부분의 예측시간에서 CNN이 가장 낮은 RMSE와 가장 높은 Corr을 보였으며, 원 예보는 중간 수준, QM은 상대적으로 낮은 성능을 보였다. 특히 QM의 경우 분포 스케일 보정 효과로 평균 편향을 줄이는 데에는 유리할 수 있으나, 본 데이터셋에서는 양(+)의 편향이 확대되고 상관성이 저하되는 경향이 나타났다. 이는 QM이 원 예보의 강수 유무에 대한 판단은 옳다고 고정한 채, 강수의 양만 분포에 맞춰 조정하지만, 원 예보는 강수 발생 판단의 오류가 남아있어, 단순 분포 매핑만으로는 양의 편향이 커지고 상관성이 떨어지게 된다. 반면 CNN 기반 다지점 단기강수예측 정보 보정 모델의 경우 강수의 정도뿐 아니라, 발생 유무에 대한 보정도 진행하기 때문에 이러한 한계를 완화한 것으로 보이고, 이는 기존 문헌에서의 결과와 유사하다. Steininger et al. (2023)의 ‘ConvMOS’ 연구에서는 전통적인 모델 출력 통계(Model Output Statistics, MOS) 방식들과 비교할 때 CNN 기반의 방법이 일반적으로 낮은 RMSE를 보였으며, Badrinath et al. (2023)은 MOS와 CNN 비교 시 다양한 분위수(percentile) 구간에서 QM 기반 MOS 대비 CNN이 RMSE를 약 7.4–8.9% 낮추고 Corr 3.3–4.2% 높이는 성과를 보였다. 이러한 선행 연구들과 본 연구의 QM vs CNN 비교 결과는 맥락을 같이 한다.
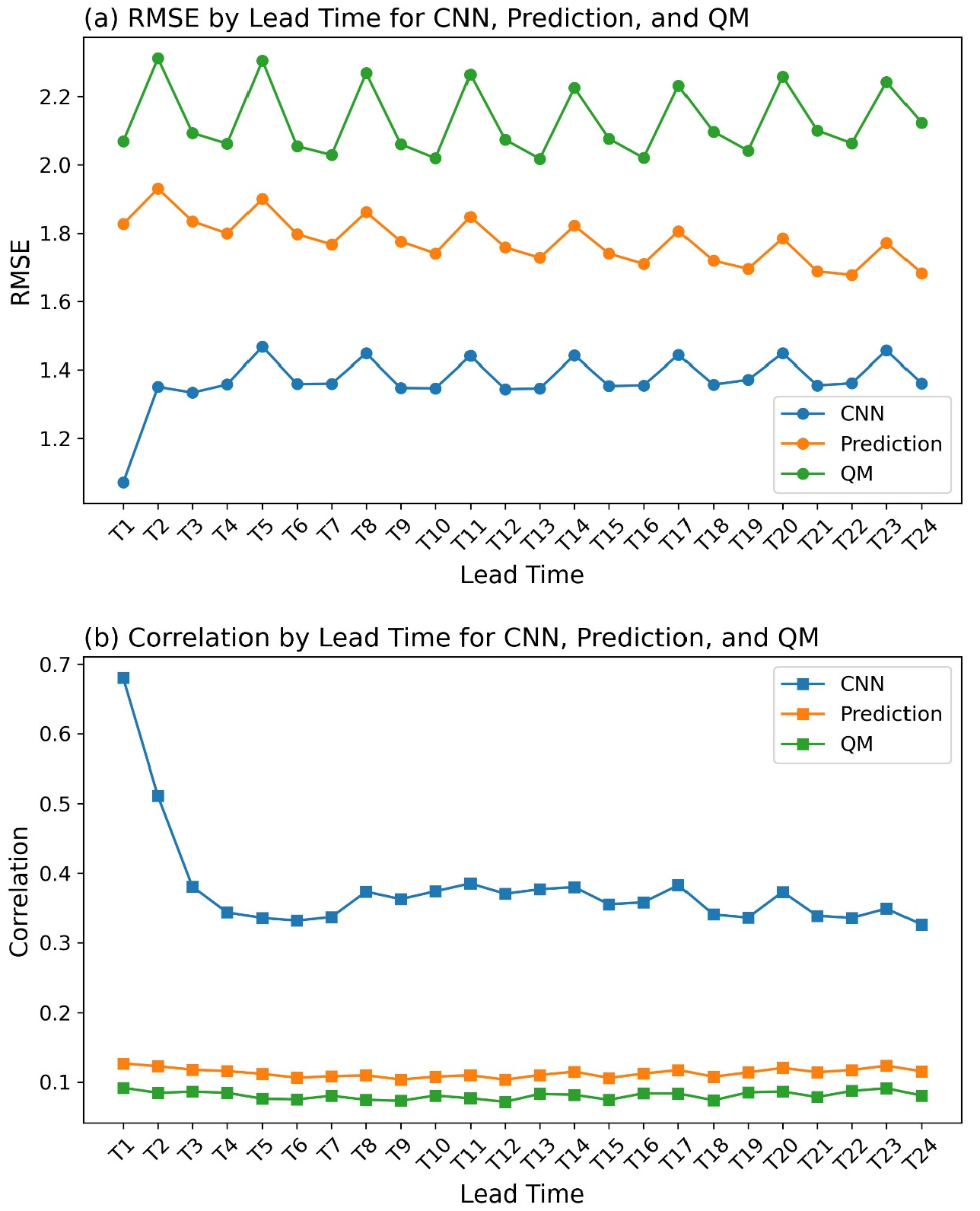
운용 관점에서, 제안 모델의 추론 소요 시간은 T=1~24 예측시간 전체를 산출하는 데 약 20 ms 내외였으며(하드웨어 사양 동일), 이는 사실상 실시간 예측이 가능함을 의미한다. 반면 QM 기법의 경우에도 수 초 이내로 계산이 가능해 속도 측면에서 큰 차이는 없으나, CNN은 통계적 보정보다 일관된 성능 개선을 보였다. 따라서 본 비교 실험은 동일 자료·동일 프로토콜 하에서 CNN 기반 보정이 전통적 통계 보정보다 강건하고 신뢰성 있는 향상을 제공한다는 점에서 의미가 있다.
5. 결 론
본 연구는 기상청 동네예보 데이터를 기반으로 CNN 모델을 개발하여 78개 지점의 1~24시간 예측시간 강수 예측을 수행하였다. 테스트 결과, 제안한 모델은 국지예보모델 대비 RMSE를 평균 16.50% 감소시키고 Corr을 53.90% 향상시켰으며, 특히 단기 예측(T<6)에서 뚜렷한 성능 개선을 보였다. 이러한 결과는 제안 모델이 공간 패턴 학습을 통한 예측 보정에 효과적임을 보여준다.
첫째, CNN 기반 후처리 모형이 예측 성능을 개선할 수 있음을 확인하였다. 합성곱 계층이 동네예보의 구조적 오차를 보정하고, 단기 예측시간에서의 개선 효과가 장기 리드 타임까지 영향을 끼쳐 전체 예측 성능을 향상시켰다. 이는 Sadeghi et al. (2021)이 보고한 강수 후처리 성능 향상과 유사한 결과이며, 본 연구에서는 특히 초기 예측시간에서의 개선 폭이 크게 나타났다.
둘째, 강수예측 정보 보정에서 관측자료가 성능개선에 효과적임을 보였다. T=1에서 관측 강수량을 직접 입력한 구조는 RMSE를 37.16% 감소시키고 Corr을 174.42% 증가시켜 초기 예측의 신뢰도를 극대화하였다. 이러한 효과는 Jiao et al. (2022)의 시계열 입력 확장 접근과도 일치하며, 관측 자료 활용이 초기 오차 최소화에 결정적인 역할을 한다는 것을 보여준다.
셋째, 기상청 기준(1시간 50 mm/3시간 90 mm 이상, 또는 1시간 72 mm 이상)에 따라 극한 강수를 정의하고 검증한 결과, CNN은 절대 강도를 완벽히 포착하지는 못했으나 원 예보 대비 극한 강수의 발생 경향을 보다 근접하게 재현하였다. 이는 이벤트 기반 지표(CSI)와 유사한 성격의 평가로, CNN 보정 기법이 극한 상황에서도 일정 수준 이상의 성능 개선을 제공함을 보여준다.
다섯째, 전통적 통계 기법인 QM과 CNN 기반 단기강수예측 정보 보정 기법을 비교한 결과 QM은 평균 편향을 줄이는 데는 효과적이었으나, 전체 RMSE와 Corr 측면에서는 CNN 기반 단기강수예측 정보 보정 기법보다 낮은 성능을 보였다. 이는 강수의 불연속적 분포와 시간적 구조를 고려하지 못하는 QM의 한계 때문이며, 반대로 CNN 기반 단기강수예측 정보 보정 기법은 공간·시간 패턴을 동시에 학습하여 전 예측시간에서 일관된 개선을 보였다. 이를 통해 CNN 기반 보정 기법의 실질적 우월성을 확인할 수 있었다.
또한 실제 운용 적용성을 평가하기 위해서는 예보 발표 이후 일정 시간 내 추론 속도와 처리 파이프라인 구축에 대한 검증이 필요하다. 본 연구에서 학습된 CNN 모델을 이용해 미래 24시간 예측자료를 전체 보정 수행한 결과, 추론 시간은 약 20 ms 내외로 실시간 적용이 가능함을 확인하였다. 이는 QM 등 전통적 통계 기법과 유사한 속도를 유지하면서도, 일관된 성능 개선을 제공한다는 점에서 의미가 있다. 따라서 향후 모델 경량화 및 시스템 최적화 연구를 통해 대규모 운영 시스템에도 적용 가능성을 확장할 수 있을 것으로 기대된다.
종합적으로, 본 연구에서 개발한 CNN 모형은 강수 예측의 정확성을 높이는 효과적인 후처리 프레임워크를 제시하였으며, 특히 관측 자료와 공간 패턴 학습의 결합이 단기 예측 성능 향상에 핵심적인 역할을 함을 규명하였다. 기후변화로 인한 극한 강수 빈도가 증가하는 상황에서, 본 연구의 방법론은 수해 예측 정확성 향상과 재해 대응력 강화에 기여할 수 있을 것으로 기대된다. 향후에는 LSTM 결합, 다변량 입력, 데이터 증강 등을 통해 장기 예측 안정성과 지점 간 성능 균형을 개선할 계획이다.
