

1. 서 론
2. 자 료
3. 기계학습 알고리즘
3.1 Randomforest
3.2 XGBoost
3.3 Light Gradient Boosting Model
4. 예측 모형 구축 방법
5. 결 과
6. 결론 및 토의
1. 서 론
가뭄이란 인류에게 가장 큰 피해를 주고 있는 자연재해 중의 하나이다. 가뭄은 진행속도가 느리고 그 피해를 정량적으로 파악하기 힘든 어려움을 갖고 있다. 또한, 최근 지구 온난화 현상에 의한 지구의 연평균기온 상승으로 인해 가뭄으로 인한 피해는 지속적으로 증가하고 있다(Park et al. 2013). 기후변화로 인해 증가할 가뭄의 위험은 Intergovernmental Panel on Climate Change (IPCC) 보고서에서도 찾아볼 수 있다. IPCC에서는 증가된 강수의 강도와 변동성이 수많은 지역에서 홍수 범람과 가뭄의 발생 위험을 증가시킬 것으로 전망하고 있다. 또한, 여름 동안 대륙의 내륙지역, 특히 저위도 및 중위도에 위치한 아열대 지역에서 건조해지는 경향이 더하여 언제든지 극심한 가뭄을 겪게 될 지역의 비율이 증가할 것으로 보고 있다(Bates et al. 2008). 이렇게 기후변화로 인해 가뭄의 위험이 증가할 것으로 예상되어왔고, 그로 인한 피해를 예측하고 줄이고자, 가뭄 위험도를 예측하기 위한 다양한 연구들이 진행되었다.
Park et al. (2012)은 전국 229개 행정구역별 가뭄 위험도 지도를 나타냈다. 미국(National Drought Mitigation Center)에서 제안한 가뭄 위험도 정의를 바탕으로 가뭄 위험도 지수(Drought Risk Index)를 가뭄 노출성 지수(Drought Hazard Index)와 가뭄 취약성 지수(Drought Vulnerability Index)의 곱으로 정의하였다. 1974년부터 2007년까지의 일 강우량을 이용하여 Byun and Wilhite (1999)가 개발한 유효가뭄지수(Effective Drought Index, EDI)를 산정하였다. 해당 연구에서는 시간 단위가 월 단위인 파머강우지수(Palmer Drought Severity Index)와 표준강수지수(Standard Precipitation Index, SPI) 대신 시간 단위가 일 단위인 EDI를 사용하여 가뭄의 시작과 끝을 명확하게 하여 가뭄의 발생 확률을 효과적으로 평가할 수 있게 했다. Kim et al. (2020)은 베이지안 의사결정나무 기법을 이용한 혼성 모형을 구성하여 기존에 사용하던 단순한 동적 모형이나 통계적 모형보다 더 정확하게 표준강수지수(SPI)를 예측했다. Yoon et al. (2020)은 가뭄 위험도 판정을 위해 Moderate Resolution Imaging Spectroradiometer 위성 영상을 이용하여 국내 재배환경 및 지형적 특성을 고려할 수 있는 500 m 해상도의 증발스트레스지수(Evaporative Stress Index)를 산정하였다. Kim et al. (2022)은 댐의 유입량이 정상년보다 적은 경우를 가뭄으로 정의하였고, 가뭄의 지속기간과 심도를 기반으로 수문학적 이변량가뭄빈도해석을 수행하여 가뭄의 재현기간을 도출하는 연구를 진행하였다. Seo et al. (2022)는 시나리오와 기존에 제시된 가뭄지수를 이용하여 가뭄 위험도를 예측하는 연구를 진행했다. IPCC가 제시한 대표농도경로(Representative Concentration Pathway) 시나리오와 공통사회경제경로(Shared Socioeconomic Pathways) 시나리오를 조합하여 6개의 미래 시나리오를 구축하였다. 시나리오와 가뭄지수 Standardized Runoff Index를 채택하여 한반도 5개 대권역(한강, 낙동강, 금강, 영산강, 그리고 섬진강)과 111개의 중권역을 대상으로 가뭄 위험도를 산정했다.
가뭄 위험도를 평가하고 예측하는 데에는 다양한 방법들이 사용되어 왔다. 많은 가뭄의 위험도를 평가하는 지수가 활용되고 있는데 이런 지수들은 가뭄의 영향을 직접적으로 평가하지 않고 간접적으로 가뭄의 영향을 평가해야 하는 한계점이 있다. 실제 피해 사례를 이용하여 가뭄으로 인해 피해를 보는 사람들에게 와닿는 지표를 얻은 연구는 많지 않다. 이런 문제를 보완하고자 우리는 실제 가뭄 피해 사례 자료를 이용하여 가뭄 피해의 위험도를 정량화 하는 방법론을 개발하였다.
본 연구에서는 가뭄의 위험도가 가뭄의 영향을 비상급수 자료가 대표할 수 있을 것으로 생각하여 가뭄 시 비상급수 발생 예측이 가뭄의 위험도를 예측할 수 있다고 가정하였다. 비상급수의 경우 특정한 조건에 따라 발생하는 것이 아닌 의사결정자가 다양한 환경 조건을 보고 비상급수를 결정한다. 그래서 일반적인 방법론으로는 비상급수 예측 모형을 개발하는 것이 어려울 것으로 판단되어 본 연구에서는 기계학습 기법을 활용하여 기상학적 및 수문학적 환경 조건을 기준으로 비상급수를 판단하는 모형을 개발하였다. 기계학습 모델로는 이진분류에 적합한 Randomforest, eXtreme Gradient Boosting (XGBoost), Light Gradient Boosting model (LightGBM)을 사용하였으며, 가뭄에 영향을 주는 수문학적 요소들을 입력 자료로 하고 가뭄 피해의 위험도 기준이 될 비상급수 데이터를 출력 자료로 하여 예측을 수행하였다. 개발된 가뭄 위험도 정량화 및 예측 방법론의 적용성 및 성능을 평가하기 위해서 전라도 지역을 대상으로 사례연구를 진행하였다. 본연구에서 개발된 방법론은 가뭄의 위험도 정량화 및 영향 예측에 활용이 가능할 것으로 기대된다.
2. 자 료
비상급수가 자주 시행되는 전라도의 여수, 완도, 임실, 정읍, 장수, 장흥, 고흥을 대상 지역으로 선정하였다. 가뭄으로 인한 비상급수 예측을 수행하기 위한 수문학적 요소로 기상 데이터, 댐 데이터, SPI를 사용하였다. 가뭄 피해의 위험도 기준으로는 비상급수 데이터를 사용하였다.
기상 데이터는 가뭄 발생 요인인 평균 풍속, 일 평균 기온, 일 평균 상대습도, 일 평균 일조를 사용하였다. 종관기상관측(Automated Synoptic Observing System)에서 지역별로 수집하였다. 연구에서 활용한 지점의 평 균 풍속과 일평균 기온 평균과 표준편차는 Table 1에 정리되어 있다. 활용지점의 위치는 Fig. 1에 나타나있다. 일 평균 상대습도와 일 평균 일조시간의 평균과 표준편차는 Table 2에 정리되어 있다.
Table 1.
Means and standard deviations of wind speed and air temperature for the used weather stations
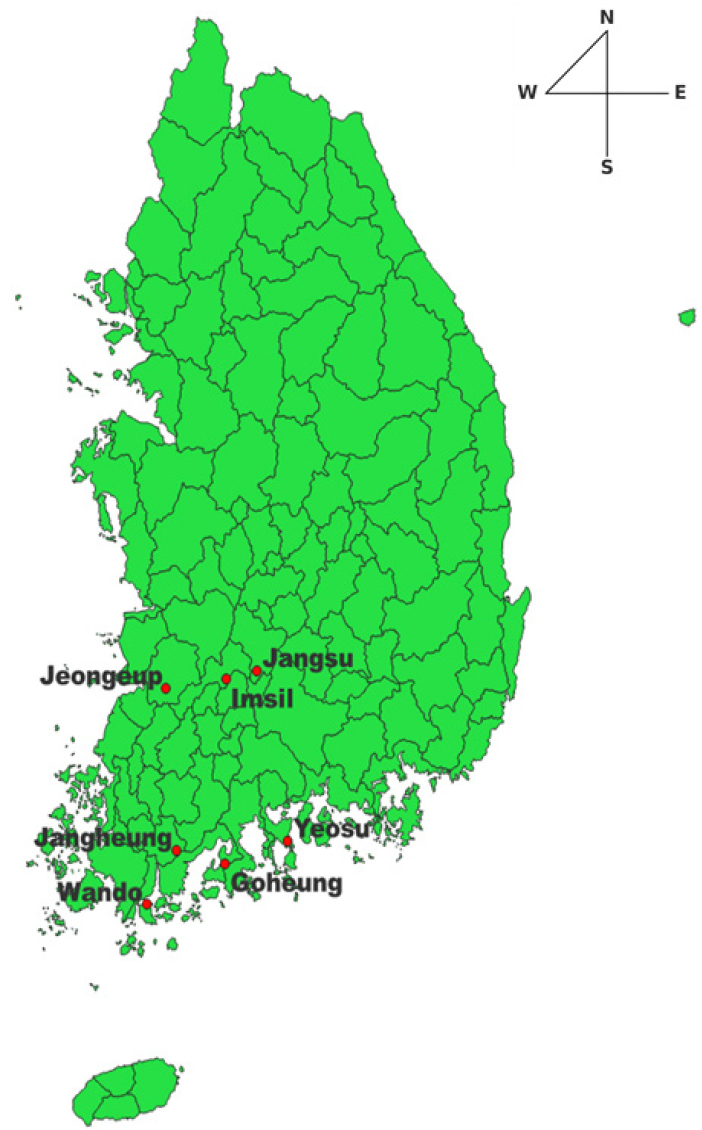
Table 2.
Means and standard deviations of relative humidity and sunlight time for the used weather stations
SPI 지수는 특정한 시간에 대한 강우량의 평균과 강우량의 차이를 표준편차로 나눈 것이다. 우리나라의 강우 형태는 Gamma 분포를 따르고 Gamma 분포의 확률밀도함수는 다음과 같다.
여기서, 𝛼 > 0 𝛼 : 형상매개변수
𝛽 > 0 𝛽 : 규모매개변수
x > 0 x : 확률변수(강수량)
이를 평균이 0이고 표준편차가 1인 정규분포로 변환하여 계산한 결과가 SPI 지수이다(Kim et al. 1998) SPI 지수는 SPI3, SPI6, SPI12를 사용하였으며, 지역별로 수집하였다. SPI 지수를 사용하는 것은 장기적인 강수 패턴을 분석할 수 있어, 강수량 데이터를 사용하는 것보다 가뭄의 영향을 더 잘 고려할 수 있다. SPI3, SPI6은 한국수자원공사 및 기상청에서 수집하였고 SPI12는 실시간 미제공하여 기상데이터로 계산하였다. 사용한 SPI3, SPI6, SPI12의 평균과 표준편차는 Table 3에 정리되어 있다.
Table 3.
Means and standard deviations of SPI3, SPI6, and SPI12 for used weather stations
댐 수문자료는 댐 총방류량 및 댐 수위로, 물 수요량을 대체할 수 있다고 판단하여 사용하였다. 댐은 전라도 지역의 부안댐, 평림댐, 장흥댐, 섬진강댐, 주암(본)댐, 동복댐, 보성강댐, 주암(조)댐, 수어댐, 주암역조정지댐으로 선정하여 각각의 총방류량과 수위를 수집하였다. 댐 데이터는 한국수자원공사에서 수집하였다. 활용한 댐 수문자료의 평균과 표준편차는 Table 4에 정리되어 있다.
Table 4.
Means and standard deviation of water level and total outflow for the used dams
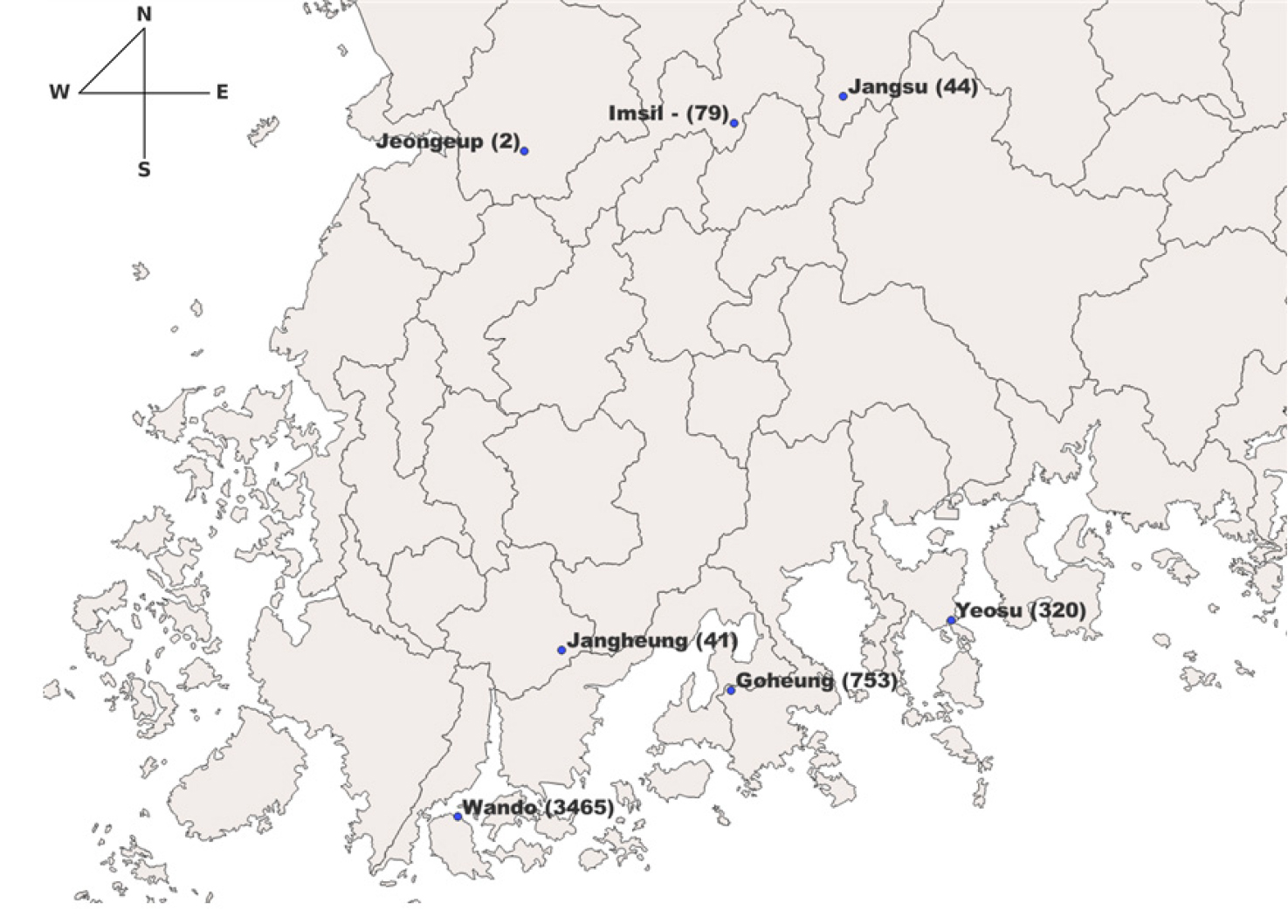
비상급수는 가뭄 등으로 인한 물 부족 지역에 시행하는데, 단계적으로 제한급수와 운반급수가 있다. 비상급수 데이터는 국가가뭄정보포털의 단비 가뭄 지원 서비스로 데이터를 요청하여 지역별로 수집하였다. 시군구 단위로 되어있는 대상 지역과 형식을 맞추기 위해서, 읍면동 단위의 데이터를 시군구 단위로 바꾸어 사용하였다. 동일한 시군구 내에서 같은 날짜에 여러 읍면동에서 비상급수가 발생한 경우, 이를 모두 1번의 발생으로 간주한다. 도서 지역의 경우 가뭄으로 시행한 비상급수가 아닐 수 있기에 대상 지역에서 제외한다. 비상급수 발생을 1, 미발생을 0으로 하여 이진분류 모델에 알맞게 바꾸어 사용했다. Fig. 2는 대상 지역을 나타난 지도이다.
3. 기계학습 알고리즘
모델은 Randomforest, XGBoost, LightGBM을 사용하였다. Kim et al. (2020)에서 소개된 연구에서 가뭄 예측에 앙상블 모형을 사용하였고 이 앙상블 모형에는 부스팅 기법과 Randomforest가 포함되어 있다. 이 연구에서 부스팅 기법과 Randomforest는 좋은 성능을 보였고, 우리 연구에서도 좋은 성능이 기대되어 부스팅 기법인 XGBoost, LightGBM과 Randomforest를 적용하였다.
3.1 Randomforest
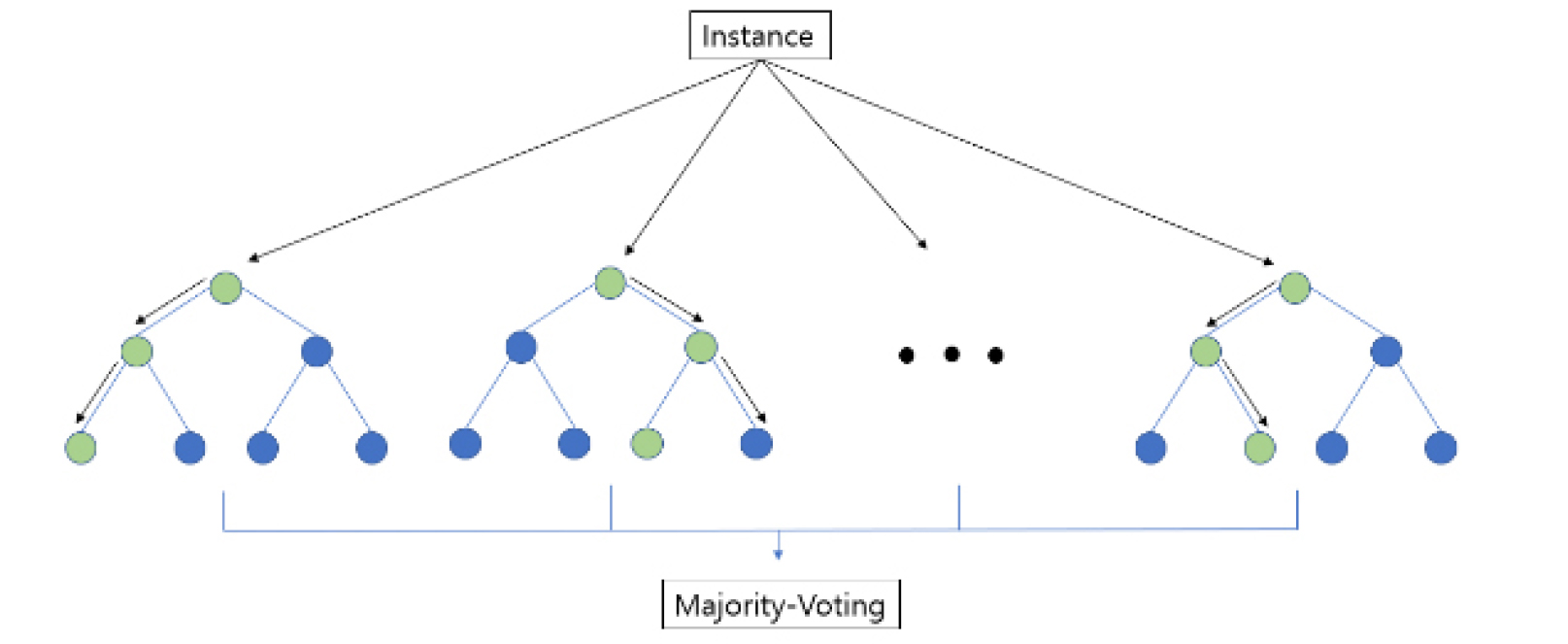
Randomforest는 Breiman (2001)에 의해 제안된 앙상블 학습(ensemble learning) 기반 모형이다. 앙상블 학습이란 여러 개의 분류기를 생성하고 각각의 예측을 결합하여 보다 정확도가 높은 예측을 도출하는 기법이다. Randomforest는 배깅(Bagging)의 기본 원리에 무작위성을 추가하여 성능을 향상시킨 방법이다. 배깅의 기본 원리는 중복이 가능하게 원본 데이터를 여러 개의 데이터셋으로 나눈 뒤, 각 데이터셋을 여러 개의 모델로 독립적으로 학습시킨 후, 각 모델의 예측 결과를 평균하거나 투표하는 방식으로 결합하여 최종 예측 결과를 만드는 것이다. 변수의 개수가 m개일 때 한다면 Randomforest는 일반적으로 각 분할에서 무작위로 m/3개의 변수를 선택하여 트리를 만든다. Randomforest에서 변수의 중요도는 훈련 데이터에서 j번째 특징의 값을 치환하고, 다시 데이터에 대하여 Out-of-bag 오차(OOB-오차)를 구하여 치환 전의 OOB-오차의 차이를 평균하여 정의한다. Raondomforest 모형의 구조는 Fig. 3에 나타나 있다. 큰 중요도 점수를 갖는 변수는 작은 중요도 점수를 갖는 변수보다 높은 순위의 중요성을 갖는다. Randomforest는 데이터와 변수를 무작위로 추출하여 서로 조금씩 다른 나무들로 구성되었기 때문에 각 나무들의 예측값은 서로 상관이 없게 되어 일반화 성능을 향상시킨다(Choi et al. 2017).
3.2 XGBoost
XGBoost는 선형 모델이나 트리 기반 모델에서의 데이터 과적합 문제를 해결하고, 규모가 큰 데이터셋의 안정성을 향상시키고 훈련 속도를 빠르게 하기 위한 목적으로 만든 방법이다(Lee and Sun 2020). Gradient Boosting이란 여러 개의 약한 학습기(weak learner)를 조합하여 사용하는 앙상블 학습 중 하나인 Boosting 기법에 오류식을 최소화하는 방향으로 반복적으로 가중치 값을 업데이트하는 방법인 경사 하강법을 적용한 것이다. XGBoost는 나무 구조(Tree) 형태로 데이터를 나누는 의사결정나무(decision tree)를 약한 학습기로 이용한다(Sim et al. 2022).
XGBoost는 분류와 회귀에서 우수한 성능을 발휘한다. 기술적인 측면에서 순차적으로 가중치를 증가시켜 학습하는 Gradient Boosting Machine (GBM)과는 다르게 XGBoost는 병렬수행을 통하여 GBM보다 빠른 학습 속도를 가진다(Sim et al. 2022). Eq. 3은 앙상블 모델을 표현하는 식이다.
여기서 는 예측값, 는 Tree의 개수, 는 공간에 k번째 의사결정나무, F는 모든 의사결정나무의 집합이다. Chen and Guestrin (2016)에서 소개된 XGBoost는 손실함수를 정규화하여 Regularized Boosting기술을 만들었다(Sim et al. 2022).
여기서 좌측항인 는 실제 값과 예측 값의 차이인 손실함수(loss function)이며 우측항인 모델의 과적합을 방지하는 정규화항이다(Sim et al. 2022). 최종 예측 모형 개발을 위해서 손실함수가 최소가 되는 Eq. 3를 학습을 통하여 계산한다.
3.3 Light Gradient Boosting Model
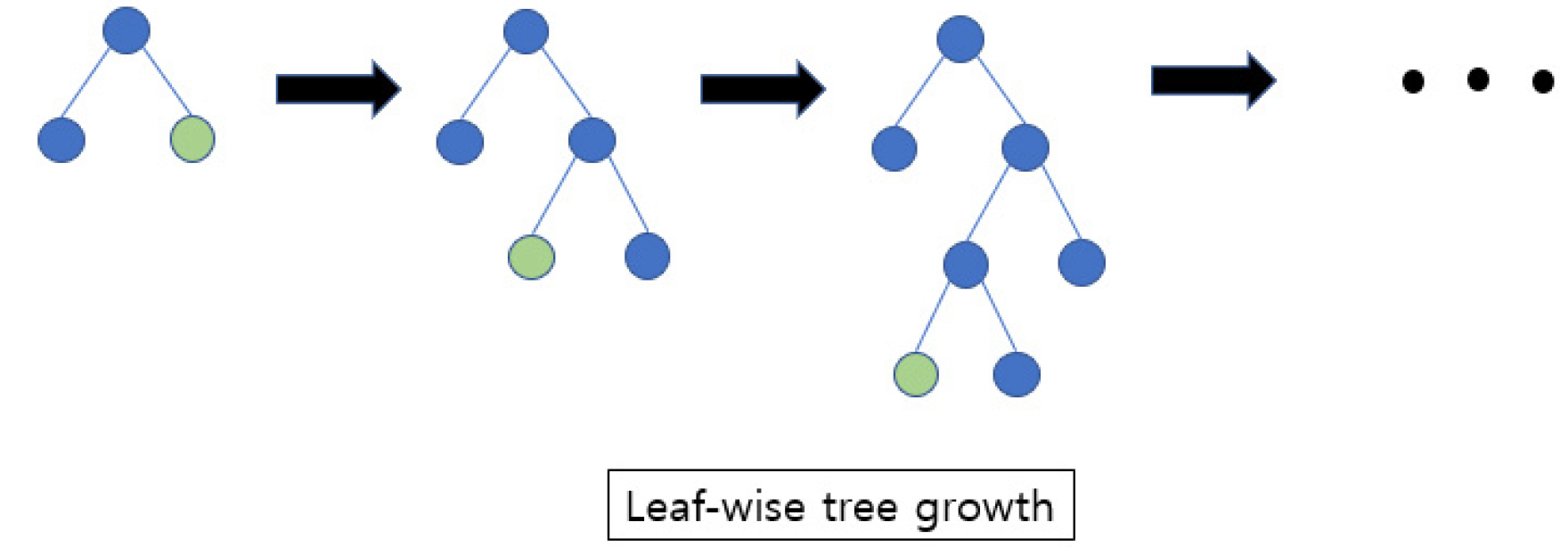
LightGBM은 그래디언트 부스팅(Gradient Boosting) 프레임워크로 XGBoost 알고리즘의 속도를 개선하기 위해 만든 모델이다. 일반적인 트리 기반 알고리즘은 수평적 생장(level-wise)을 활용하지만, 이와 다르게 LightGBM은 수직적 생장(leaf-wise)을 활용한다. 최대 손실 값(Max Delta loss)을 갖는 리프 노드를 지속적으로 분할하면서 깊이가 깊고 대칭적이지 않는 트리를 생성한다. 이렇게 생성된 트리는 반복적으로 학습하여 예측 오류 손실을 최소화한다(Seo and Hwang 2022). LightGBM의 모식도는 Fig. 4에 표현되어 있다.
100개 이상의 매개 변수를 커버하기 때문에 LightGBM은 파라미터 튜닝이 복잡하다. 파라미터는 최적의 값을 결정하기에 중요하며, 모델의 정확도를 향상시키기 위해서는 파라미터 튜닝이 필수적이다(Han and Joe 2022).
수평적 생장을 활용하는 XGBoost 알고리즘보다 학습 시간 및 예측 수행 시간이 더 빠르고, 메모리를 적게 사용하는 것이 장점이다. 하지만 데이터의 양이 적을 때는 모델이 과적합 될 수 있다는 단점이 있다(Jang et al. 2023)
4. 예측 모형 구축 방법
본 연구는 case1, 2, 3 순서로 진행되었다. Case1은 지역과 시계열에 상관없이 모든 지역의 데이터를 합친 총 데이터에서 60%를 학습 데이터로 20%를 검증 데이터 20%를 평가 데이터로 사용하여 결과를 산출하였다. 이때, 이진분류의 데이터 불균형 문제를 막기위해 균형 잡힌 데이터(balanced data set)를 사용하였다. Case2는 Case1에서의 총데이터를 지역별로 나누었으며, 시계열을 적용하여 2022년의 데이터를 평가 데이터로 하고 나머지 데이터의 75%를 학습데이터로 25%를 검증데이터로 사용하여 성능평가의 결과를 산출하였다. Case3는 Case2에서 가장 성능이 좋았던 지역을 선택하 여, 같은 비율로 성능평가를 하였고 임계값에 따른 예측 확률을 나타내는 그래프를 산출하였다. 각 case의 자료 구성 정보는 Table 5에 정리되어 있다.
Table 5.
Comparison of predictive model development for case 1, case 2, case 3
5. 결 과
Table 6, Fig. 5은 case1의 모델 별 성능평가 결과이다. Randomforest의 경우 F1-score는 0.9683, AUC는 0.9962, XGBoost의 경우 F1-score는 0.9835, AUC는 0.9979, LightGBM의 경우 F1-score는 0.9917, AUC는 0.9998로 모두 좋은 성능을 보였다. ROC curve는 세 개의 모델 모두 곡선이 왼쪽 상단 코너에 가까이 위치한 것으로 보아 거의 완벽한 분류성능을 보인다고 할 수 있다. Confuse Matrix에서 LightGBM의 경우 False Positive (FP)가 17개, True Positive (TP)가 835개로, 양성으로 예측된 데이터의 대부분이 실제 양성인 경우가 훨씬 많아 정밀도가 높다고 할 수 있다. 그리고 False Negative (FN)이 6개로 세 개의 모델 중 가장 낮아, 실제 양성을 거의 놓치지 않아 재현율도 우수하다고 할 수 있다. Randomforest는 FP가 43개, TP가 827개, FN이 14개로 LightGBM보다 FP와 FN이 좀 더 많아 정밀도가 더 낮고 할 수 있다. XGBoost는 FN이 8개, FP는 21개로 LightGBM, Randomforest의 중간 개수이며, 두 모델 사이의 성능을 보인다고 할 수 있다.
Table 6.
Case 1 – comparison of model performance evaluation results
| Model | F1-Score | AUC |
| Randomforest | 0.9683 | 0.9962 |
| XGBoost | 0.9835 | 0.9979 |
| LightGBM | 0.9917 | 0.9998 |
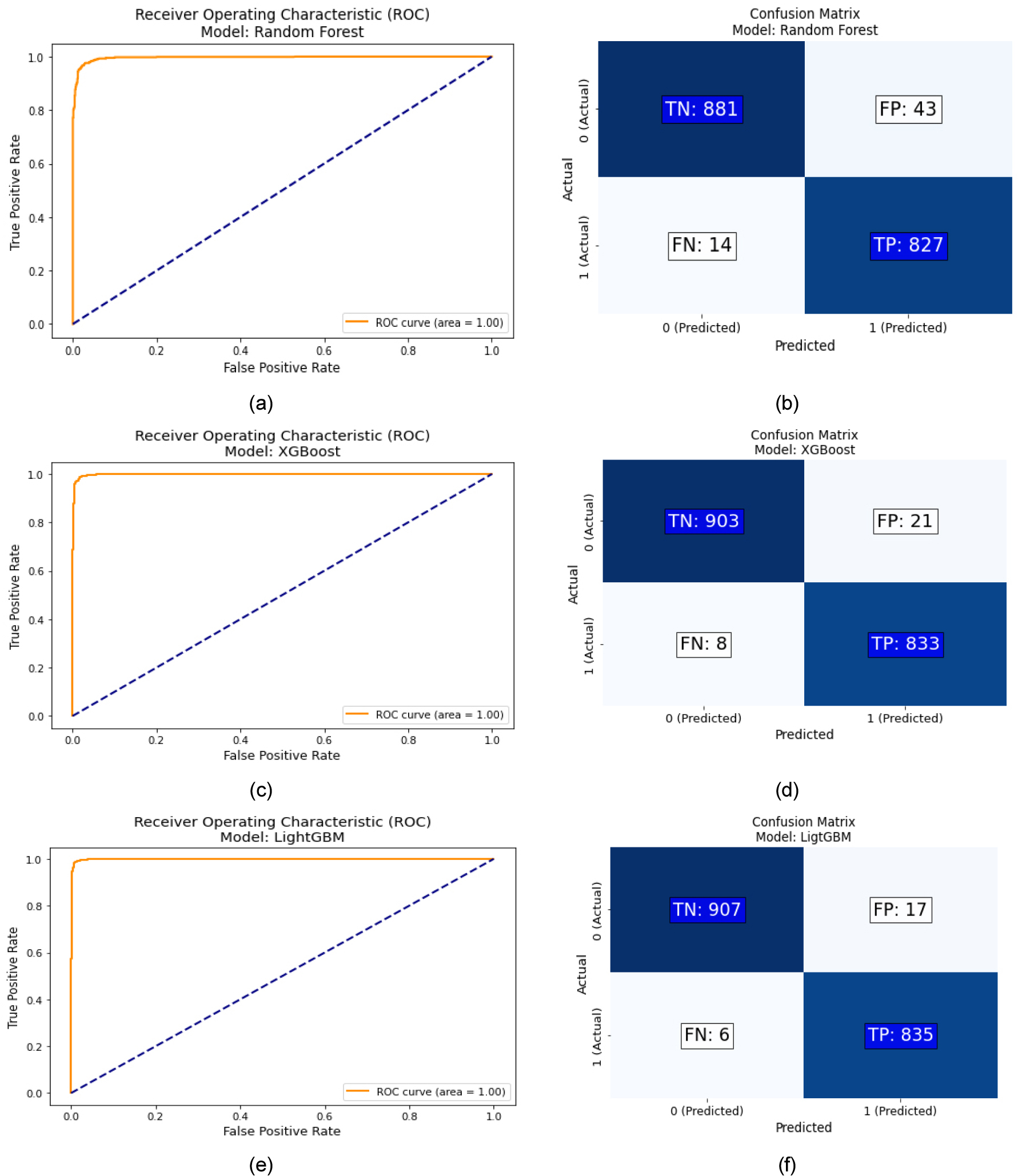
Table 7은 case2의 지역별 성능평가 결과이다. 완도지점을 제외한 나머지 지점은 F1-score가 산정되지 않았고 AUC값은 0.8도 되지 않아 보통의 성능을 보였다. 하지만 완도지점의 F1-score는 0.9416, AUC는 0.9893로 좋은 성능을 보였다.
Table 7.
Case 2 – comparison of performance evaluation results by region
| Station | Goheung | Yeosu | Wando | Jangheung | Imsil | Jangsu |
| F1-Score | 0 | 0 | 0.9416 | 0 | 0 | 0 |
| AUC | 0.3961 | 0.4126 | 0.9893 | 0.6563 | 0.7928 | 0.5596 |
Table 8, Fig. 6는 case3의 모델 별 성능평가 결과이다. Randomforest의 경우 F1-score는 0.9617, AUC는 0.9973, XGBoost의 경우 F1-score는 0.9848, AUC는 0.9943, LightGBM의 경우 F1-score는 0.9635, AUC는 0.9971로 모두 좋은 성능을 보였다. ROC curve는 case1과 매우 비슷한 결과가 산출되었다. Confuse Matrix에서 LightGBM인 경우 FP가 1개밖에 없고 TP가 277개로, 양성으로 예측된 데이터가 실제로도 양성인 경우가 더 많기 때문에 정밀도가 높은 편이라고 할 수 있다. 그리고 FN이 20개로 적지 않게 존재하여, 실제 양성인 경우를 일부 놓치고 있지만 대부분의 양성을 잘 탐지하고 있기 때문에 재현율도 우수한 편이라고 할 수 있다. Randomforest인 경우 FP가 1개, TP가 276개, FN이 21개로 LightGBM과 매우 비슷하여 정밀도와 재현율이 LightGBM과 비슷한 수준이라고 할 수 있다. XGBoost인 경우 FN이 6개로 다른 모델에 비해 눈에 띄게 낮은 편으로 재현율이 매우 높은 편이라고 할 수 있다. 하지만 FP가 3개로 작은 차이지만 조금 많아 정밀도는 약간 낮을 것이다.
Table 8.
Case 3 – comparison of model performance evaluation results
| Model | F1-Score | AUC |
| Randomforest | 0.9617 | 0.9973 |
| XGBoost | 0.9848 | 0.9943 |
| LightGBM | 0.9635 | 0.9971 |
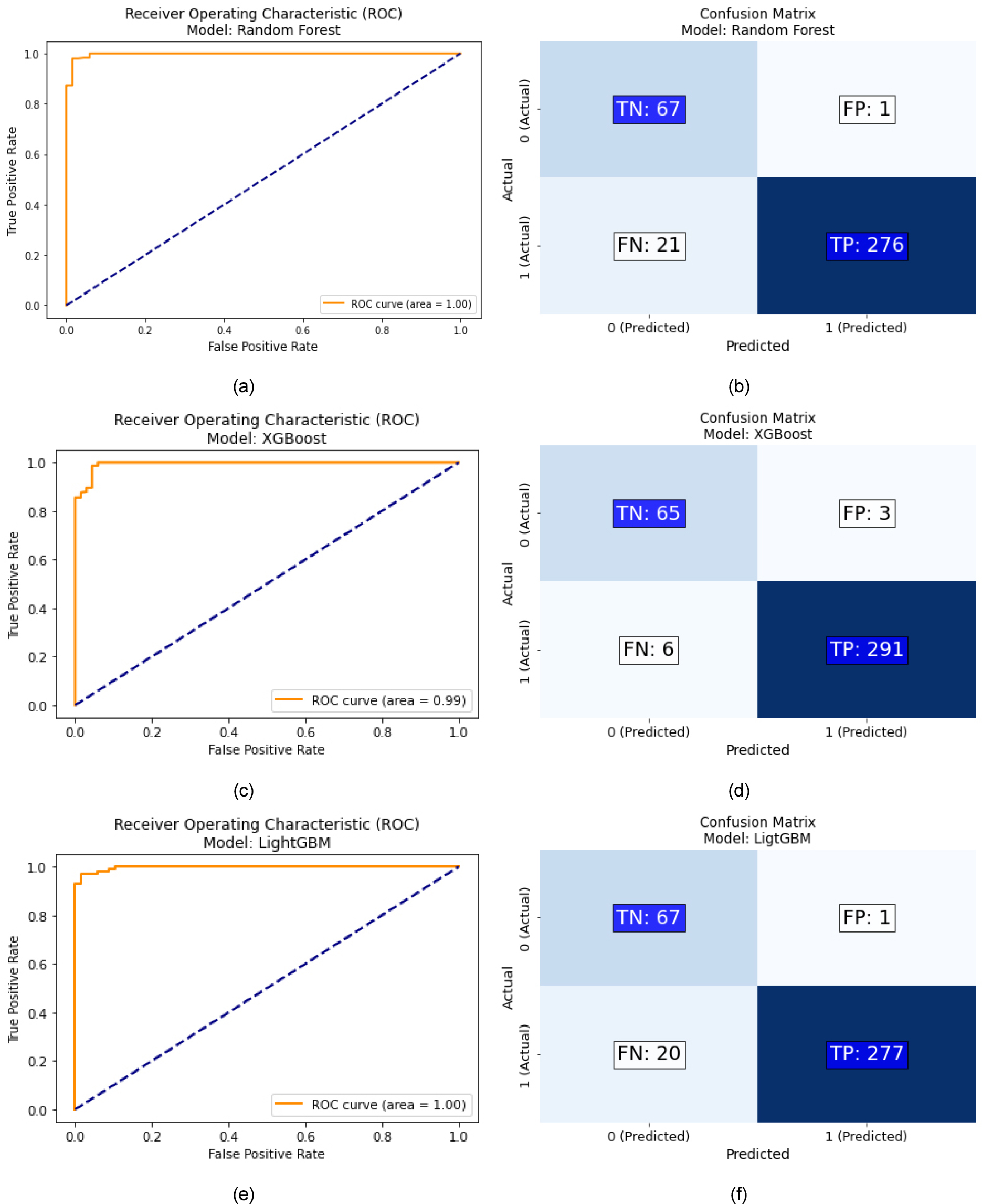
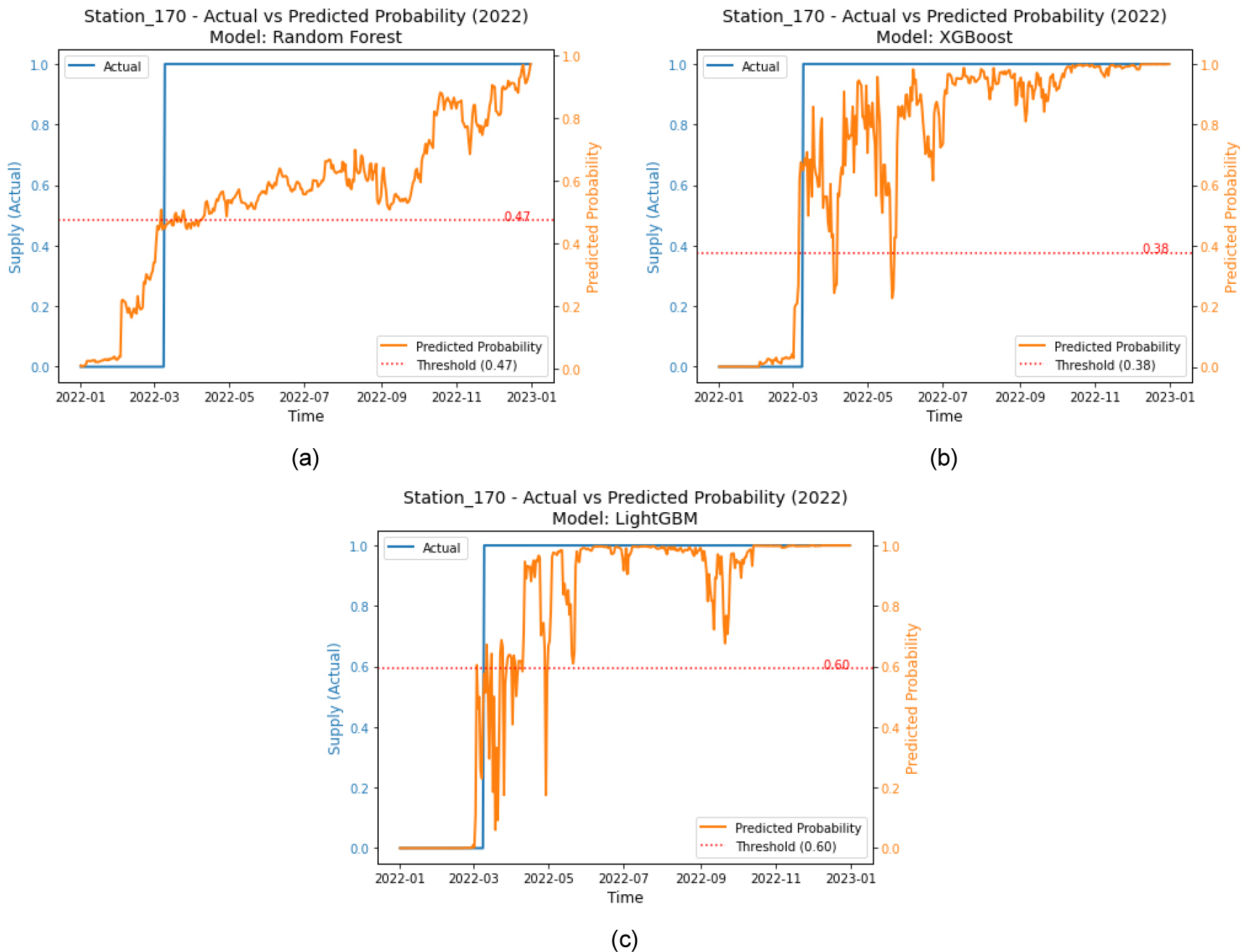
Fig. 7는 최종적으로 case3에 대해 임계값에 따른 실제값과 예측값을 비교하는 결과이다. 각 모델마다 0과 1로 나누는 기준인 최적의 임계값을 계산해야 그 임계값을 기준으로 최적의 결과값을 산출할 수 있다. LightGBM의 경우 임계값은 0.6이며, 실제값이 1이되는 시점 초반구간의 예측확률이 매우 낮아 보이지만 후반구간은 안정적으로 1에 수렴하는 결과를 보인다. Randomforest의 경우 임계값은 0.47이며, 예측값이 0에서 1까지 점진적으로 증가하면서 실제값과 비교했을 때 안정적인 결과를 보인다. XGBoost의 경우 임계값은 0.38이며, LightGBM과 매우 비슷한 경향을 보이지만 변동성이 좀 덜하고 후반구간 또한 안정적으로 1에 수렴하는 결과를 보였다. 따라서 그래프의 예측값의 분포를 보면 Randomforest는 0과 1을 확실하게 예측하지는 못하지만 실제값과 맞지 않는 값을 보이는 경우가 상대적으로 거의 없으며, XGBoost와 LightGBM은 0과 1을 확실하게 예측하지만 실제값과 맞지 않는 값들이 눈에 띄게 보이는 특징이 있다.
6. 결론 및 토의
본 연구는 인공지능 모델을 사용하여 가뭄 피해의 위험도를 확률로 예측하고 임계값을 기준으로 예측값을 정량화하고자 하였다. 인공지능 모델로는 이진분류에 적합한 Randomforest, XGBoost, LightGBM을 사용하였으며, 가뭄에 영향을 주는 수문학적 요소들을 입력 자료로 하고 가뭄 피해의 위험도 기준이 될 비상급수 데이터를 출력 자료로 하여 예측을 수행하였다. Case1, 2, 3의 순서로 진행되었고, case마다의 한계점을 개선해나가며 연구를 진행하였다.
case1은 지역과 시계열에 상관없이 데이터를 구성하였다. 입력과 출력에서 0과 1의 비율을 균형있게 맞춰 성능평가를 한 결과로 Randomforest, XGBoost, LightGBM 모두 1에 가까운 F1-Score와 AUC 값으로 좋은 성능을 보였다. 하지만 균형잡혀 있지 않은 실제 사례인 비상급수 데이터를 사용하였는데, 인위적으로 데이터를 균형있게 맞춰 평가를 하는 것은 결과에 신뢰성이 부족하다고 판단했다.
이러한 case1에 대한 한계점을 해결하기 위해서 case2로는 지역별로 데이터를 나누고 비상급수가 가장 많이 발생한 2022년 데이터를 출력으로 사용하여 지역별로 비교를 해보았다. 그 결과로는 여수, 완도, 임실, 정읍, 장수, 장흥, 고흥지역 중에 완도지역만 1에 가까운 F1-score와 AUC 값으로 좋은 성능을 보였고, 다른 지역의 F1-score는 모두 0 그리고 AUC는 0.8도 넘지 못하는 좋지 않은 성능을 보였다. 이 결과에따라 완도지역을 제외한 나머지 지역은 비상급수 데이터가 불충분하여 F1-Score를 산출해내지 못하는 문제가 생겼다고 판단했다.
따라서 case3로 완도지점만을 선정하여 비상급수가 가장 많이 발생했던 2022년 데이터를 출력으로 하였고, case1과 같은 세 가지의 모델로 성능평가를 하였다. 그 결과 세 모델 모두 1에 가까운 F1-Score, AUC 값으로 좋은 성능을 보였으며, 임계값에 따른 실제값에 대한 예측값의 시각화 또한 양호한 형상을 보였다.
가뭄에 대응하기 위해서 수자원를 효과적으로 관리하는 것이 중요하다. 가뭄 위험도를 예측하는 것도 그만큼 중요하다고 판단된다. 시나리오를 사용하거나, 어떤 상황을 가정하여 가뭄 위험도를 예측한 다른 연구들과 다르게, 본 연구는 실제 가뭄 피해 사례를 이용하여 높은 정확도를 가진 결과를 얻었다. 하지만 처음에는 전라도 전체지역을 목표로 했지만 실제 가뭄 피해 사례인 비상급수 데이터가 부족하였고, 데이터의 불균형 문제라는 한계점이 명확히 나타났다. 따라서 시간이 지나 데이터가 모인다면 완도 지역뿐만 아니라 다른 지역에서도 적용할 수 있는 결과를 얻어, 가뭄 피해를 줄이는 연구를 지속적으로 진행할 것이다. 또한, 본 연구에서 수행한 정확도 높은 가뭄 예측은 해당 지역의 수자원 관리에 직접적인 도움이 될 것이다.
